I am trying to re-implement Krizhevsky et al. (2012) using PyTorch, and I am confused how precisely the second and the third convolutional layers of the AlexNet model communicate (and same for inputs from the fifth to the sixth layer, and from the sixth to the seventh layer, although I am omitting this in my question here).
In the figure below, there are two “filters” that pass the output from the top half to next top half but also the bottom half. Similarly, the bottom half has two “filters” that pass the output to the next bottom and top half.
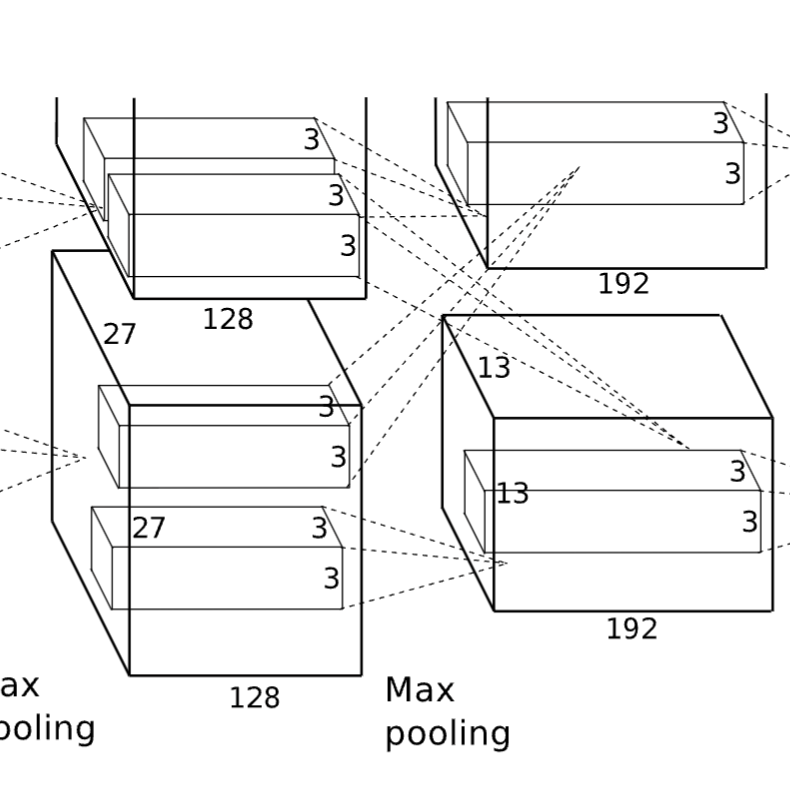
My main question: How are the outputs of the second layer being passed to the third layer?
I read the paper, and unless I missed something, it seems that the authors didn’t precisely outline how the outputs are being passed from the second to the third layer. I skimmed through a bunch of blogposts and git repositories, and most descriptions are high-level and most implementations don’t seem to split the model between two GPUs.
The most relevant thing I could find was the following sentence from the convnet2 readme:
Here, the layers conv2a and conv2b take both conv1a and conv1b as inputs. An implicit copy operation is performed in order to get the output of conv1a into the input of conv2b, as well as the output of conv1b into the input of conv2a.
My best guess is that the out_channels parameter in the second layers should actually be 64 instead of 128, and then the output from both the top and bottom layer should be concatenated as torch.cat([output_from_top_half, output_from_bottom_half], dim=1) and passed to the top and bottom half of the third layer. I am unsure if my understanding here is correct, though.
I am confused what’s the correct interpretation here, and would appreciate any helpful pointers!