I’m trying to run this bit of code, and expecting the final matrix multiply to work asynchronously while the copies happen. Im surprised that the trace actually shows the operations to be synchronous
Even if I remove the streams, the same trace occurs.
import torch
import time
stream1 = torch.cuda.Stream()
stream2 = torch.cuda.Stream()
stream3 = torch.cuda.Stream()
N = 1000
mul = 5
num = 1000
qs = []
for i in range(num):
qs.append(torch.rand(N, N, device='cuda:3'))
q2 = torch.rand(mul * N, mul * N, device='cuda:5')
rs = []
for i in range(num):
rs.append(torch.rand(N, N, device='cuda:4'))
r2 = torch.rand(mul * N, mul * N, device='cuda:6')
from torch.profiler import profile, record_function, ProfilerActivity
## Warm up
for q in qs:
q @ q
for r in rs:
r @ r
q2 = q2 @ q2
r2 = r2 @ r2
for i in ['3', '4', '5', '6']:
temp = 'cuda:{}'.format(i)
print(temp)
torch.cuda.synchronize(torch.device(temp))
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof2:
for q in qs[:len(qs) // 2]:
q.to('cuda:5')
q2 = q2 @ q2
q2 = q2 @ q2
for r in rs[:len(qs) // 2]:
r.to('cuda:6', non_blocking=True)
r2 = r2 @ r2
r2 = r2 @ r2
for i in ['3', '4', '5', '6']:
temp = 'cuda:{}'.format(i)
print(temp)
torch.cuda.synchronize(torch.device(temp))
with torch.cuda.stream(stream1):
for q in qs[len(qs) // 2:]:
q.to('cuda:5')
q2 = q2 @ q2
q2 = q2 @ q2
with torch.cuda.stream(stream2):
r2 = r2 @ r2
r2 = r2 @ r2
with torch.cuda.stream(stream3):
for r in rs[len(qs) // 2:]:
r.to('cuda:6', non_blocking=True)
prof2.export_chrome_trace('check12.json')
The trace seems to shows concurrency for both sets of workloads, which very much surprised me and made me think I dont really understand :(.
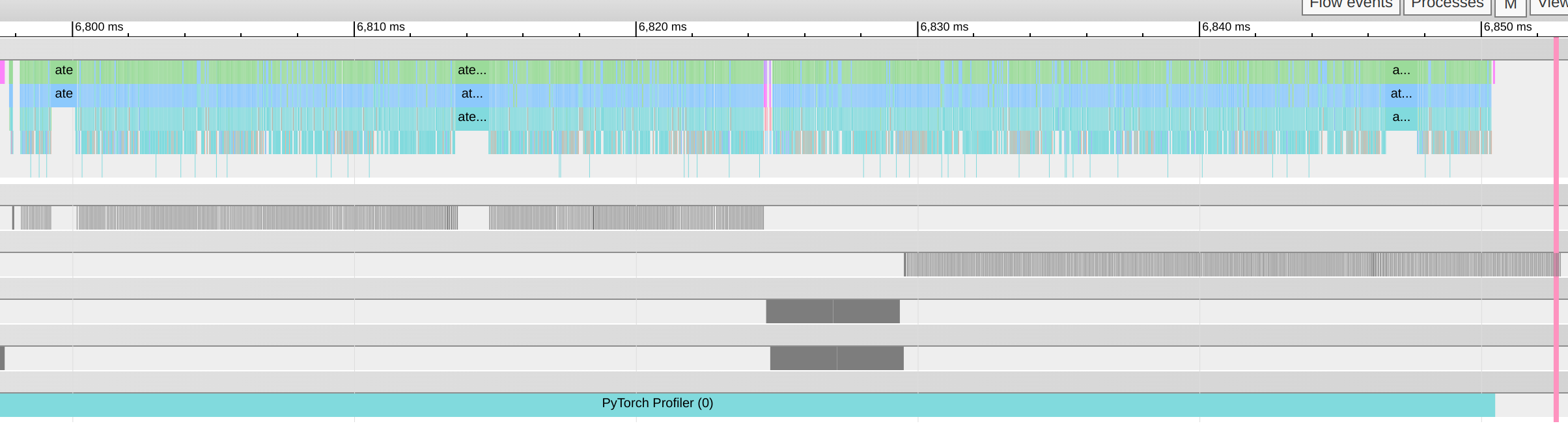
Zooming in to GPU:4 and GPU:6
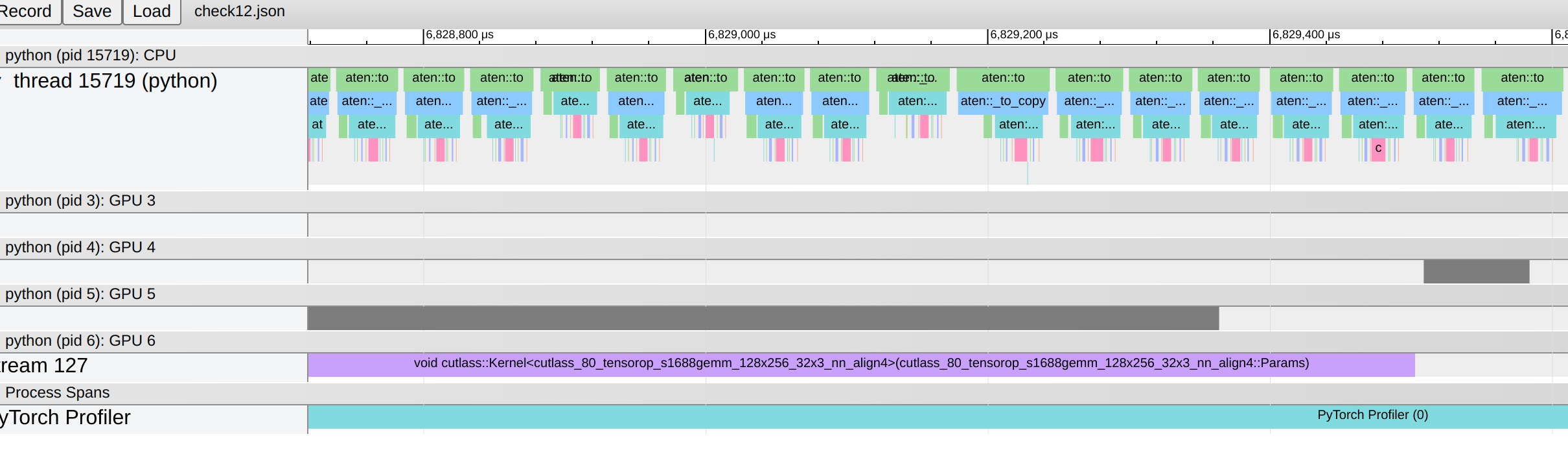
Im surprised that stream 3 waits on stream 2 (even if I flip the order I get the same behavior). Removing the stream contexts didn’t really generate the async behavior I expected either ![]()
Dhruv