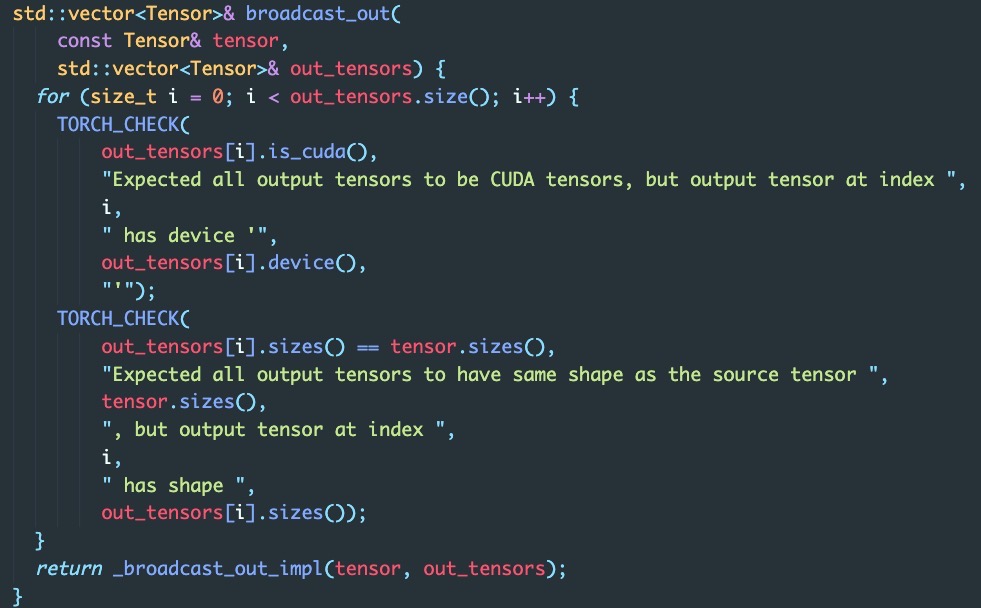
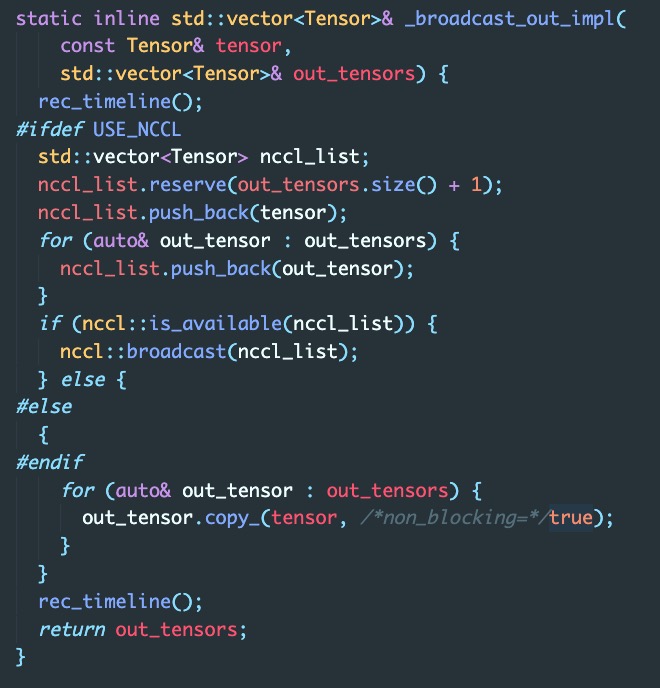
I have some questions on Data parallel broadcasting. Dose it broadcast layer by layer or gather all parameters of the whole model? I can find some C++ codes of it in “/torch/csrc/cuda/comm.cpp”, such as :
I have two GPUs, one called GPU0 which is the main GPU and another is GPU1.
I have added some logs in the python files(torch/nn/parallel/comm.py). The results show that it broadcasts layer by layer.
If it broadcasts layer by layer, another question is that does the GPU1 receive the next layer’s parameters from GPU0 and make computation at the same time? Thanks for your attention and answers !
Oh! Thanks a lot! I’m clear now. 十分感谢!!
The “params” in function “replicate” are the layers of my model, and the “buffers” is the buffer, but I still not know what “modules” means in function “replicate” of ‘torch/nn/parallel/replicate.py’. Can you help me ?
The number of “modules” is only one more than the “params”, and is the “for key, param in module._parameters.items():” loop really the place to replicate for every layer?