I have a set of pictures for the working principle of nn.Dataparallel:
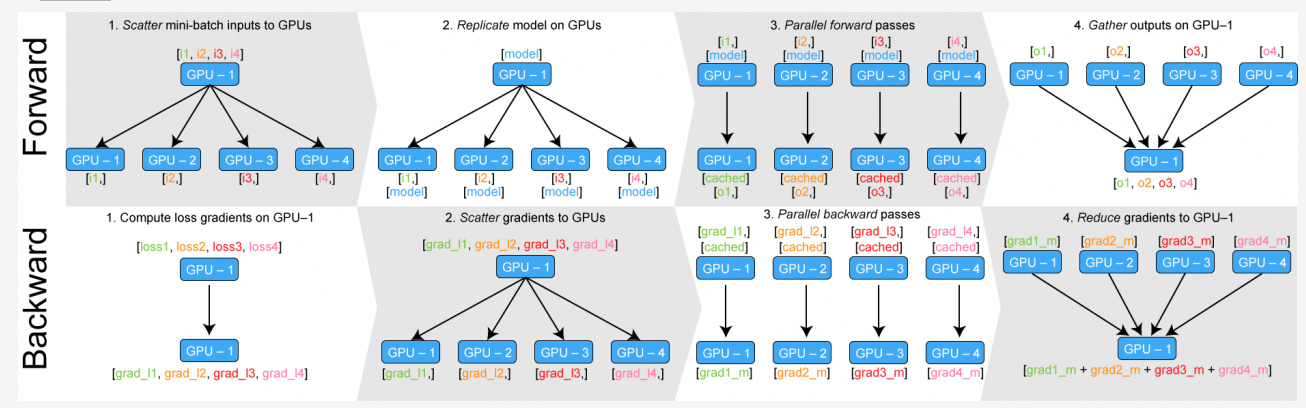
I have a question on the last picture. How does gradients actually gather on the main GPU? If there’s a Conv2d, its related gradient on GPU:0 is w0 (with shape (256, 128, 3, 3)) and its related gradient on GPU:1 is w1 (with shape (256, 128, 3, 3)). So the final gradient for this Conv2d on GPU:0 is w0 + w1 ? And the ‘+’ here means element-wise add?