Looks like it launches the kernels layer by layer sequentially, but I heard that launching CUDA kernel is asynchronous, so CPU thread does not wait for the kernel to be completed.
So, could someone explain to me how these kernels can be launched asynchronously? In other words, how can the kernel for layer N be launched without waiting for the result from the layer N-1? Thanks!
The kernels are launches on the same CUDAStream and will thus be executed in order. The execution is still asynchronous and the CPU can thus run ahead and enqueue the next kernel without blocking on the return value.
If you are using e.g. data-dependent control flow (e.g. by checking a value of an output tensor in a condition) PyTorch will synchronize for you, since the actual return value is needed to select the next code execution path.
I have a follow-up question on that:
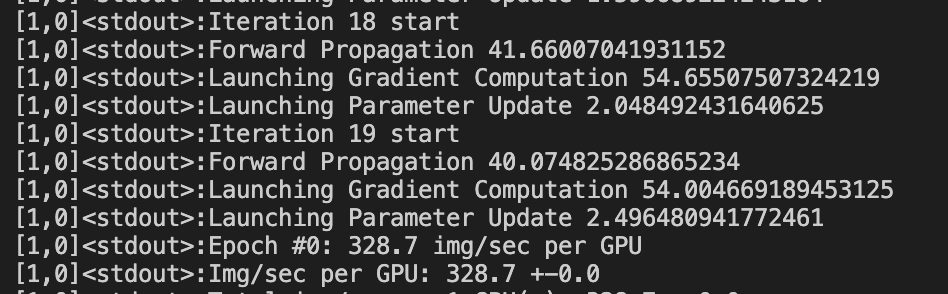
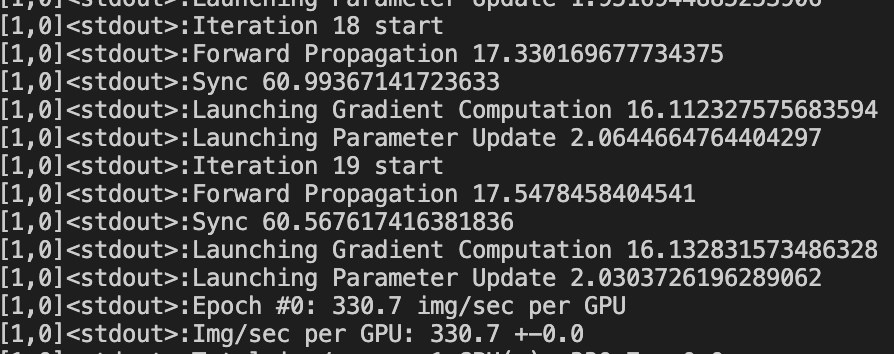
The overhead for the host thread to launch (enqueue) kernels to the CUDAStream is bigger when GPU is busy? I observe that the time for each step varies quite a lot depending on whether I run cuda.synchronize() in each iteration. Here is the details.
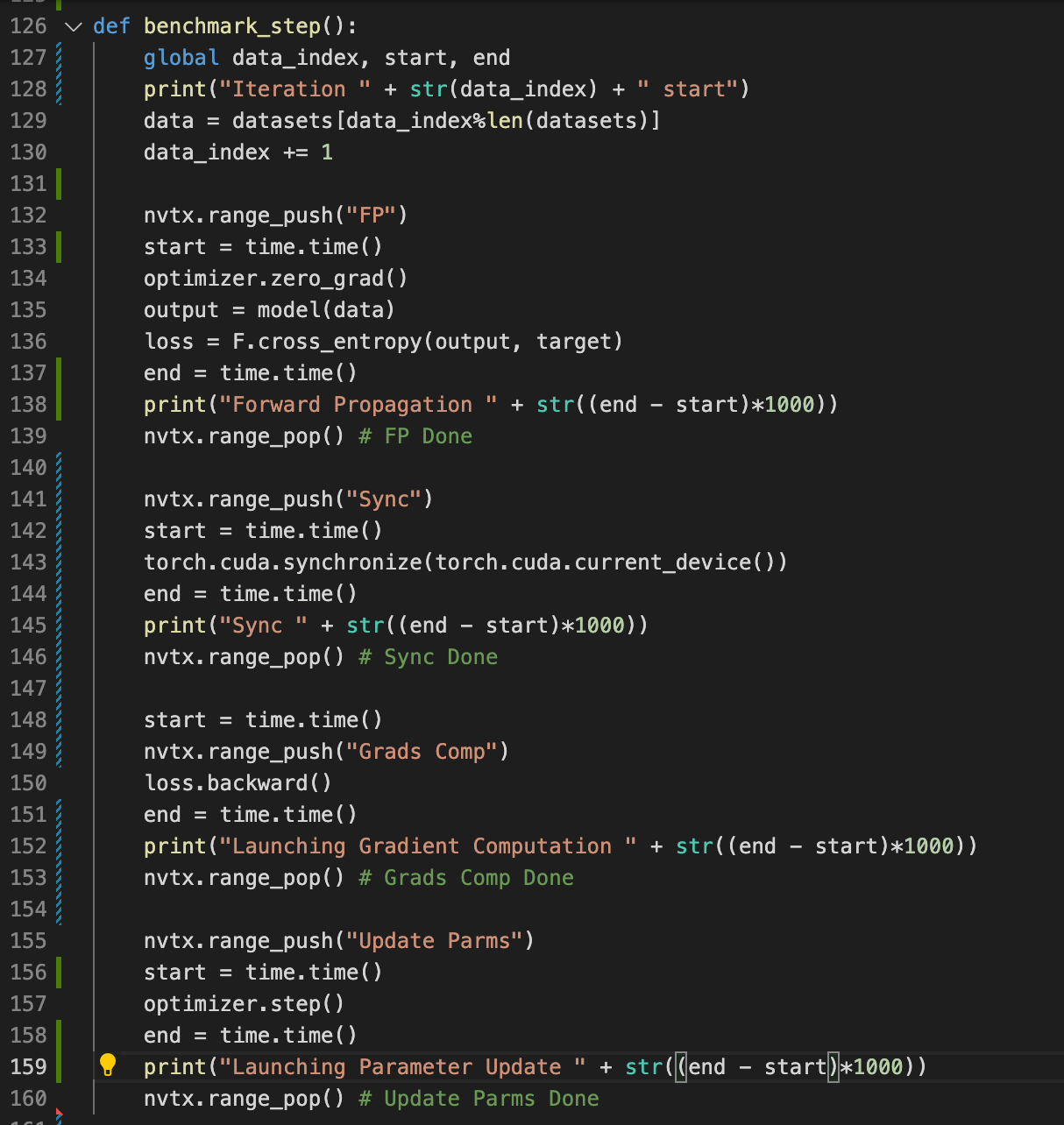
This is the iteration code I’m trying (I run it without enabling the nsys profiler):
Here, I observe that launching kernels for forward propagation takes ~17ms, and for gradient computation takes ~16ms.
It looks quite weird to me that asynchronous kernel launches (i.e., without waiting for the kernel completion) take very different times depending on the GPU’s state. Could you kindly give me any insight on this? Thanks a lot!
No, I don’t think that should be the case.
I would not dive into your profiling results as you interpreting profiling results without proper synchronizations is invalid and might be too confusing since you would need to “know” where the code would naturally synchronize.
If you are concerned about the kernel launch times, profile the code with Nsight Systems and check where the kernel launches are vs. their execution and how long each step takes.
Does it means that the PyTorch does naturally synchronize sometimes even without explicit cuda.synchronize() call?
Could you give me some typical example cases where the natural synchronizations happen?
Thanks!
Yes, some operations are performing computations on the CPU e.g. in tensor.nonzero(), each print(cuda_tensor) statement (since the CPU needs to read the actual value), memcopies if non_blocking=False and thus pageable memory is used, every control flow which needs to read tensor values (e.g. if (cuda_tensor > 0).all()).
Btw. if you are interested in reducing the kernel launch overheads (which would be especially beneficial if your actual GPU workload is small compared to the launches) you could check the CUDA Graphs util.