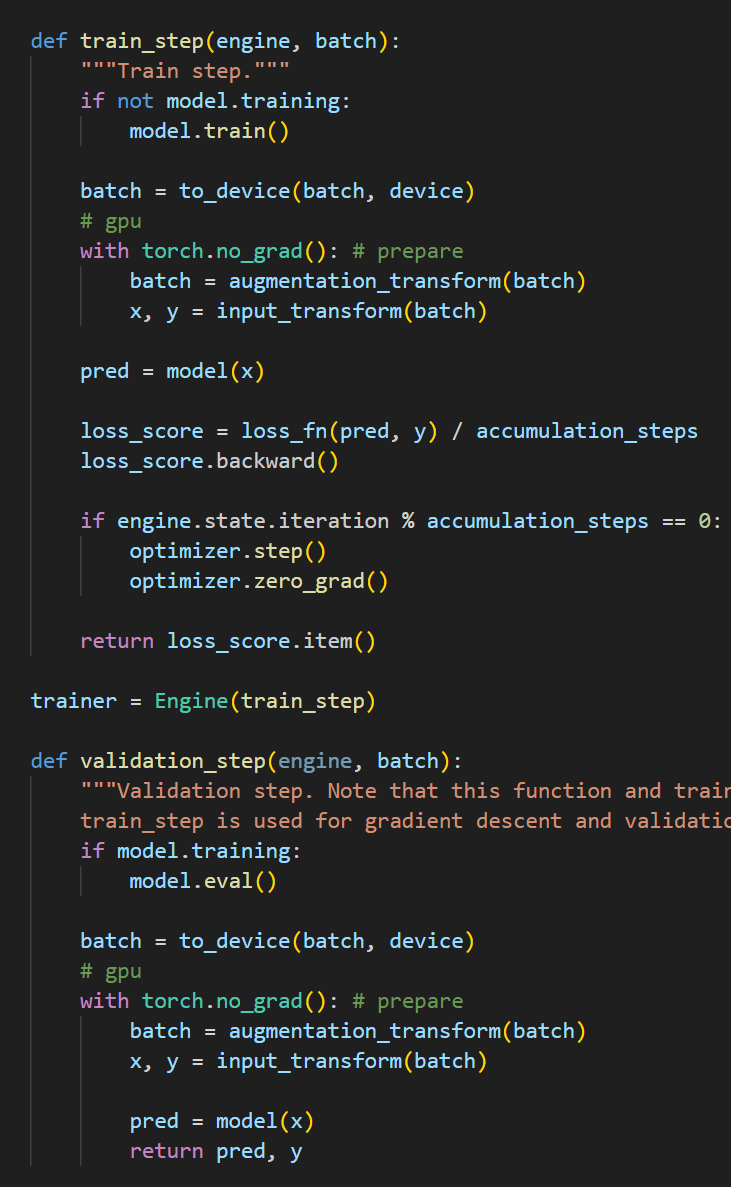
I used the Adam optimizer. If I perform an evaluation (i.e., model.train(), ...train steps... grad steps... model.eval()... model.train() in a loop) after every iteration (instead of every epoch) or after every training step when epoch length == 1, the gradients fail to descend properly. However, if I perform evaluation after every >100 iterations or increase the epoch length to a comparable scale, it works fine. It seems that model.eval() somehow affects the optimizer’s functionality.
My first question is: by what mechanism does model.eval() cause the gradients to fail to descend properly?
My second question is: if I must perform evaluation after every iteration—for instance, because I am using PyTorch for compressed sensing reconstruction and want to print the results after each iteration—what is the best way to handle this?