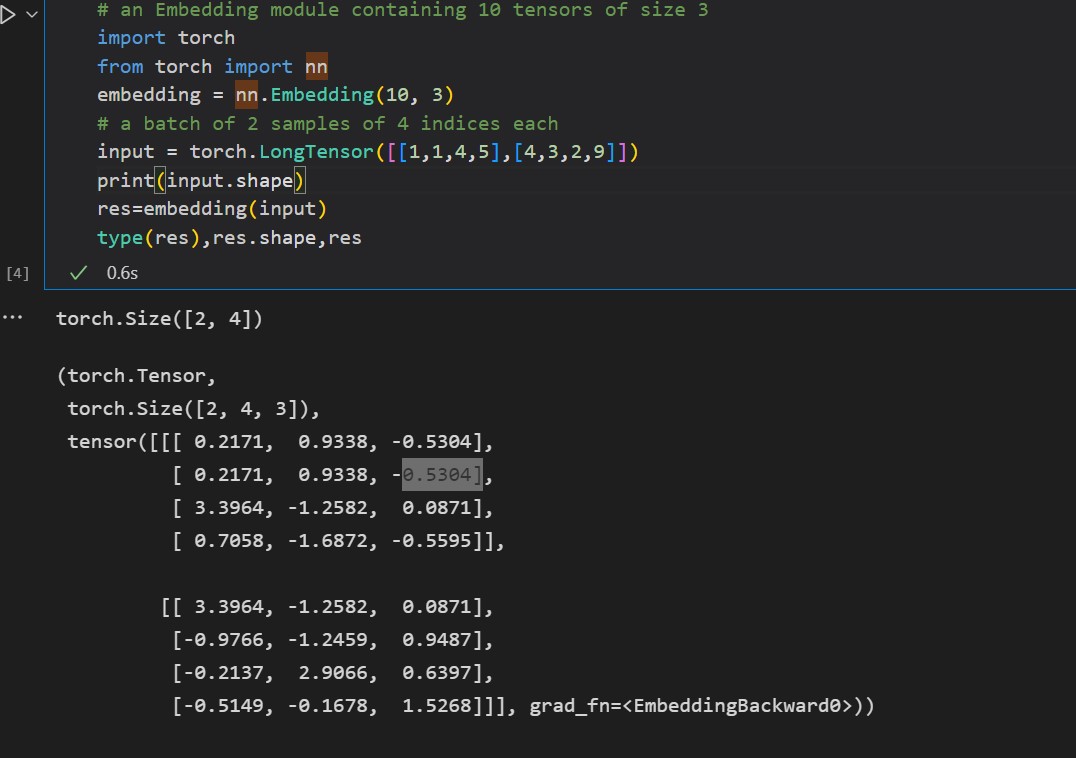
I am new in the NLP field am I have some question about nn.Embedding. I have already seen this post, but I’m still confusing with how nn.Embedding generate the vector representation. From the official website and the answer in this post. I concluded:
- It’s only a lookup table, given the index, it will return the corresponding vector.
- The vector representation indicated the weighted matrix is initialized as random values and will be updated by backpropagation.
Now my question are:
- If I have 1000 words, using
nn.Embedding(1000, 30)to make 30 dimension vectors of each word. Willnn.Embeddinggenerate one-hot vector of each word and create a hidden layer of 30 neuron like word2vec? If so, is it CBOW or Skip-Gram model? What’s the difference betweennn.Embeddingandnn.Linear - Now, I am researching about the Visual-Question-Answering tasks. Any suggestion about using pretrain vector representation, e.g. word2vec, in question vocabulary or not using it?