I am getting confused when I use torchaudio.transforms.DownmixMono.
first, I load my data with sound = torchaudio.load(). This is correct that sound[0] is two channel data with torch.Size is ([2, 132300]) and sound[1] = 22050, which is the sample rate.Then I use soundData = torchaudio.transforms.DownmixMono(sound[0]) to downsample. But the result looks weird with torch.Size([2, 1]). If I understand it correctly, I can get soundData, which has only one channel? What’s wrong with that?
I check the document as well, the input format should be: tensor (Tensor): Tensor of audio of size (c x n) or (n x c), what does (c x n) mean?
Hi @ptrblck,
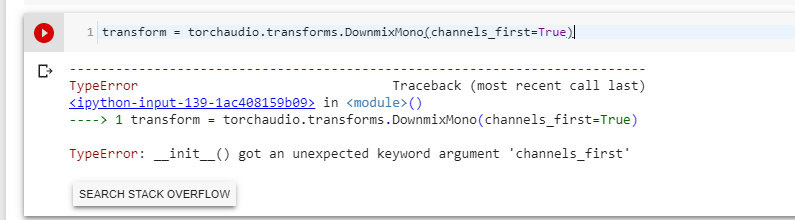
How should I pass the channels_first keyword to the DownmixMono function?
I get the following error. torchaudio.transforms.DownmixMono()(sound[0],channels_first = True) __init__() got an unexpected keyword argument 'channels_first'
However this works but I get wrong dimensions as mentioned by OP: torchaudio.transforms.DownmixMono()(sound[0])
This argument was introduced after your specified commit hash.
If you look at the file, you’ll see that the __init__ method just contains a pass statement.