Question:
- When I will do:
e1.backward(), would the gradient flow properly back to the parameters of the network? - How does this
torch.where()statement varies fromd1[c2 <= 0] = 0.0, or if-else statements (if implementable here) ? - Kindly suggest some good implementations of the mask, threshold operations allowing gradient flow across them?
Context:
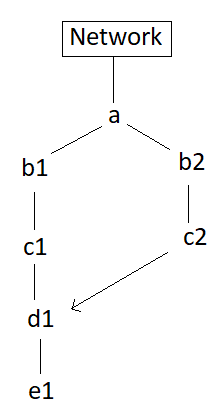
Please see the attached image for the computation flow (roughly).
d1 is the modified c1 based on the condition or mask created by c2
a: is a tensor of shape [16,3,256,256] # rgb image batch
c1, c2: single-channel tensors [16,1,256,256]
The chain a-b2-c2 includes operations like torch.round(), modulo, view, squeeze, stack, min, clone, etc.
I want to update the parameters of the ‘Network’ based on the gradient calculated from e1, considering the fact that both c1, c2 depends upon a (output of network).
Code:
...
c2 = b2.min(dim = 0, keepdim = True)[0]
d1 = torch.where(c2 <= 0, torch.tensor(0,device='cuda:0',dtype = torch.float32,requires_grad=True), c1)
...
e1.backward()