As I defined my model as following:
def forward(self, x):
x = self.quant(x)
x = self.conv1(x)
x = self.bn1(x)
x = self.act1(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.act2(x)
x = self.conv3(x)
x = self.dequant(x)
return x
and I set all Conv layers’ bias to False.
After the model been fused and per_channel quantized the model:
UNetSimplified(
(conv1): QuantizedConvReLU2d(1, 8, kernel_size=(3, 3), stride=(1, 1), scale=0.13664968311786652, zero_point=0, padding=(1, 1))
(bn1): Identity()
(act1): Identity()
(conv2): QuantizedConvReLU2d(8, 8, kernel_size=(3, 3), stride=(1, 1), scale=0.026323270052671432, zero_point=0, padding=(1, 1))
(bn2): Identity()
(act2): Identity()
(conv3): QuantizedConv2d(8, 1, kernel_size=(3, 3), stride=(1, 1), scale=0.4080895185470581, zero_point=111, padding=(1, 1), bias=False)
(quant): Quantize(scale=tensor([10.0395]), zero_point=tensor([22]), dtype=torch.quint8)
(dequant): DeQuantize()
)
I got the per_channel quantized model state dict :
OrderedDict([(‘conv1.weight’, tensor([[[[-0.0070, 0.0028, -0.0038],
[ 0.0033, 0.0013, -0.0037],
[-0.0003, 0.0009, -0.0036]]],
[[[ 0.0067, 0.0057, -0.0076],
[-0.0008, 0.0063, -0.0086],
[ 0.0045, 0.0060, 0.0061]]],
[[[ 0.0026, -0.0024, -0.0045],
[-0.0042, 0.0017, 0.0019],
[-0.0104, -0.0039, 0.0080]]],
[[[-0.0110, -0.0009, 0.0028],
[-0.0027, 0.0006, 0.0079],
[ 0.0071, 0.0073, 0.0003]]],
[[[ 0.0076, 0.0054, 0.0020],
[ 0.0002, -0.0012, -0.0043],
[ 0.0024, 0.0003, -0.0063]]],
[[[ 0.0054, -0.0210, -0.0016],
[-0.0036, -0.0062, -0.0085],
[-0.0007, -0.0003, -0.0039]]],
[[[-0.0018, -0.0002, -0.0006],
[ 0.0004, 0.0013, 0.0010],
[ 0.0009, 0.0006, -0.0004]]],
[[[-0.0006, -0.0040, -0.0030],
[-0.0035, -0.0028, 0.0012],
[-0.0013, 0.0040, 0.0029]]]], size=(8, 1, 3, 3), dtype=torch.qint8,
quantization_scheme=torch.per_channel_affine,
scale=tensor([5.4946e-05, 6.6890e-05, 8.1454e-05, 8.6305e-05, 5.9863e-05, 1.6422e-04,
1.3998e-05, 3.1696e-05], dtype=torch.float64),
zero_point=tensor([0, 0, 0, 0, 0, 0, 0, 0]), axis=0)), ('conv1.bias', Parameter containing:
tensor([ 5.8286, 1.4856, 0.2724, 0.0426, 0.3071, -0.2796, 8.4139, 1.3693],
requires_grad=True)), (‘conv1.scale’, tensor(0.1366)), (‘conv1.zero_point’, tensor(0)), (‘conv2.weight’, tensor([[[[ 0.0150, 0.0986, 0.1136],
[ 0.0064, 0.1039, 0.0300],
[-0.0032, 0.0075, 0.0236]],
[[-0.0332, 0.0246, -0.0043],
[-0.0879, -0.0075, -0.0214],
[ 0.0032, 0.0375, 0.0289]],
[[ 0.0246, 0.0697, -0.0386],
[ 0.0289, 0.0375, 0.0246],
[ 0.0547, 0.0150, 0.0632]],
[[ 0.0021, 0.0075, -0.0043],
[-0.0868, -0.0793, -0.1361],
[ 0.0246, 0.0589, -0.0150]],
[[-0.1168, 0.0086, -0.0193],
[-0.0139, -0.0375, 0.0311],
[-0.0321, -0.0289, 0.0493]],
[[ 0.0332, 0.0129, 0.0204],
[ 0.0150, -0.0364, -0.0129],
[-0.0021, 0.0032, 0.0343]],
[[-0.1168, -0.0107, 0.0150],
[-0.1275, 0.0804, 0.0493],
[-0.0729, 0.0118, 0.0118]],
[[-0.0643, -0.0171, 0.0450],
[-0.0397, -0.0343, -0.0279],
[-0.0064, -0.0407, 0.0021]]],
[[[ 0.0041, 0.0061, 0.0143],
[-0.0010, -0.0143, -0.0266],
[ 0.0583, 0.0481, -0.0665]],
[[ 0.0389, -0.0624, -0.0430],
[-0.0102, 0.0000, 0.0194],
[-0.0553, -0.0235, -0.0143]],
[[ 0.0051, -0.0829, 0.0317],
[-0.0225, -0.0860, -0.0225],
[ 0.0389, 0.0102, 0.1157]],
[[-0.0082, -0.0102, 0.0358],
[ 0.0133, -0.0123, -0.0246],
[-0.0072, -0.1013, 0.0041]],
[[ 0.0051, -0.0420, -0.0583],
[-0.0246, -0.0174, 0.0225],
[-0.0051, -0.0031, -0.0123]],
[[ 0.0143, -0.0061, 0.1177],
[-0.0532, -0.1310, -0.1085],
[-0.0553, -0.1228, -0.0676]],
[[-0.0164, -0.0061, -0.0676],
[ 0.0205, 0.0542, -0.0276],
[-0.0041, 0.0113, 0.0051]],
[[-0.0225, 0.0522, 0.0727],
[-0.0246, 0.0143, 0.0420],
[-0.0491, -0.0450, -0.0471]]],
[[[-0.0068, 0.0155, 0.0429],
[-0.0261, -0.0199, 0.0168],
[-0.0224, -0.0267, 0.0050]],
[[-0.0075, 0.0062, 0.0186],
[-0.0143, 0.0012, 0.0112],
[-0.0373, 0.0000, 0.0112]],
[[ 0.0143, -0.0522, -0.0211],
[ 0.0454, 0.0093, 0.0609],
[ 0.0168, -0.0348, 0.0019]],
[[ 0.0099, 0.0068, -0.0137],
[ 0.0162, 0.0292, 0.0323],
[-0.0025, 0.0025, 0.0186]],
[[-0.0255, -0.0205, -0.0217],
[-0.0149, -0.0758, -0.0441],
[-0.0050, -0.0155, -0.0068]],
[[-0.0280, 0.0236, 0.0510],
[-0.0311, -0.0503, -0.0317],
[ 0.0075, -0.0273, -0.0217]],
[[-0.0168, -0.0062, 0.0137],
[-0.0360, 0.0261, 0.0298],
[-0.0242, 0.0298, 0.0174]],
[[-0.0391, 0.0000, 0.0168],
[-0.0789, -0.0323, 0.0025],
[-0.0410, 0.0292, 0.0404]]],
[[[ 0.0144, 0.0108, 0.0156],
[ 0.0057, 0.0132, 0.0183],
[-0.0303, -0.0063, -0.0078]],
[[ 0.0087, -0.0255, -0.0132],
[ 0.0156, -0.0162, -0.0078],
[ 0.0303, 0.0051, -0.0069]],
[[ 0.0051, -0.0207, -0.0384],
[ 0.0213, 0.0216, -0.0201],
[ 0.0120, 0.0162, 0.0120]],
[[ 0.0018, 0.0006, -0.0072],
[-0.0006, -0.0039, -0.0198],
[ 0.0129, 0.0021, -0.0216]],
[[ 0.0195, -0.0150, -0.0180],
[ 0.0348, -0.0039, 0.0033],
[ 0.0261, 0.0204, 0.0048]],
[[-0.0045, -0.0048, -0.0075],
[ 0.0027, 0.0015, -0.0060],
[ 0.0078, 0.0039, 0.0024]],
[[-0.0141, -0.0189, -0.0234],
[ 0.0003, 0.0060, 0.0237],
[ 0.0063, 0.0156, 0.0267]],
[[ 0.0201, 0.0261, 0.0033],
[ 0.0066, 0.0096, 0.0072],
[ 0.0078, 0.0096, 0.0120]]],
[[[-0.0063, 0.0288, 0.0253],
[-0.0040, -0.0069, 0.0127],
[-0.0132, -0.0075, -0.0357]],
[[ 0.0190, -0.0046, -0.0035],
[ 0.0063, -0.0081, -0.0092],
[-0.0086, 0.0098, 0.0040]],
[[ 0.0023, -0.0737, 0.0150],
[-0.0230, 0.0006, -0.0132],
[-0.0213, -0.0058, -0.0178]],
[[-0.0173, 0.0023, 0.0098],
[-0.0345, -0.0127, 0.0029],
[-0.0104, -0.0040, 0.0069]],
[[ 0.0092, -0.0006, -0.0092],
[ 0.0213, 0.0023, -0.0213],
[ 0.0178, -0.0035, -0.0155]],
[[-0.0224, -0.0121, 0.0437],
[-0.0294, -0.0144, -0.0046],
[ 0.0201, -0.0173, -0.0345]],
[[-0.0190, -0.0063, -0.0201],
[-0.0035, 0.0248, -0.0012],
[-0.0224, -0.0092, -0.0178]],
[[-0.0207, 0.0144, 0.0196],
[-0.0115, -0.0029, -0.0006],
[ 0.0040, 0.0035, -0.0086]]],
[[[ 0.0007, 0.0355, 0.0586],
[ 0.0020, 0.0020, 0.0123],
[-0.0089, -0.0252, -0.0150]],
[[-0.0143, 0.0027, -0.0170],
[-0.0211, 0.0048, 0.0102],
[-0.0389, 0.0041, 0.0184]],
[[ 0.0157, -0.0559, -0.0211],
[ 0.0191, -0.0075, -0.0341],
[-0.0123, 0.0286, -0.0334]],
[[ 0.0109, 0.0048, -0.0116],
[ 0.0014, 0.0007, -0.0157],
[-0.0409, -0.0552, -0.0804]],
[[-0.0334, -0.0409, -0.0873],
[-0.0450, -0.0280, -0.0170],
[-0.0157, 0.0266, 0.0689]],
[[ 0.0061, -0.0143, -0.0409],
[-0.0191, -0.0191, -0.0225],
[-0.0348, -0.0266, -0.0525]],
[[-0.0157, -0.0232, -0.0102],
[-0.0055, -0.0143, 0.0232],
[ 0.0034, 0.0157, 0.0423]],
[[ 0.0055, -0.0245, -0.0423],
[-0.0239, -0.0170, -0.0273],
[-0.0136, -0.0075, -0.0198]]],
[[[-0.0227, -0.0018, -0.0141],
[ 0.0135, 0.0221, 0.0129],
[ 0.0184, 0.0663, -0.0012]],
[[ 0.0117, 0.0215, 0.0111],
[-0.0104, 0.0000, -0.0295],
[ 0.0080, 0.0049, -0.0154]],
[[ 0.0012, -0.0313, 0.0209],
[-0.0068, -0.0381, -0.0012],
[-0.0160, 0.0289, 0.0319]],
[[ 0.0018, -0.0172, 0.0049],
[ 0.0117, 0.0000, -0.0129],
[ 0.0399, 0.0270, 0.0049]],
[[ 0.0344, 0.0227, 0.0264],
[-0.0455, -0.0313, -0.0326],
[-0.0375, -0.0332, -0.0166]],
[[-0.0614, -0.0252, -0.0381],
[-0.0037, -0.0184, -0.0338],
[ 0.0061, -0.0233, 0.0037]],
[[ 0.0129, 0.0166, -0.0448],
[ 0.0227, 0.0246, -0.0780],
[-0.0043, -0.0049, -0.0571]],
[[-0.0018, 0.0154, 0.0031],
[ 0.0160, 0.0178, 0.0068],
[ 0.0080, 0.0031, 0.0043]]],
[[[-0.0203, -0.0257, -0.0095],
[ 0.0025, 0.0435, -0.0091],
[-0.0029, 0.0012, 0.0029]],
[[-0.0046, 0.0062, 0.0219],
[-0.0178, -0.0356, -0.0174],
[-0.0228, -0.0306, 0.0075]],
[[ 0.0021, 0.0211, 0.0157],
[-0.0335, -0.0530, -0.0025],
[ 0.0211, -0.0137, -0.0145]],
[[ 0.0162, 0.0211, 0.0203],
[-0.0079, 0.0062, -0.0315],
[-0.0004, -0.0058, -0.0079]],
[[ 0.0199, 0.0037, 0.0207],
[-0.0240, -0.0261, 0.0062],
[-0.0190, -0.0029, 0.0066]],
[[ 0.0203, 0.0327, 0.0075],
[ 0.0315, 0.0186, 0.0174],
[ 0.0050, 0.0029, 0.0170]],
[[-0.0033, -0.0046, -0.0162],
[ 0.0054, 0.0298, -0.0087],
[ 0.0066, 0.0070, -0.0017]],
[[-0.0352, -0.0157, -0.0145],
[-0.0033, 0.0149, 0.0141],
[-0.0025, 0.0141, 0.0248]]]], size=(8, 8, 3, 3), dtype=torch.qint8,
quantization_scheme=torch.per_channel_affine,
scale=tensor([0.0011, 0.0010, 0.0006, 0.0003, 0.0006, 0.0007, 0.0006, 0.0004],
dtype=torch.float64),
zero_point=tensor([0, 0, 0, 0, 0, 0, 0, 0]), axis=0)), ('conv2.bias', Parameter containing:
tensor([-0.3632, 1.0700, -0.6545, -0.3776, 0.8916, 0.6928, 0.6020, 0.1993],
requires_grad=True)), (‘conv2.scale’, tensor(0.0263)), (‘conv2.zero_point’, tensor(0)), (‘conv3.weight’, tensor([[[[-0.9800, -1.8201, -2.0721],
[-1.9041, -2.5761, -2.2681],
[-1.8761, -2.9961, -2.1561]],
[[-0.6160, -1.9601, -1.7361],
[-1.0080, -1.8201, -1.5121],
[-1.4841, -1.5401, -1.7361]],
[[ 0.9520, 1.7921, -1.7641],
[ 1.2041, 0.1120, -1.3441],
[-2.4921, -1.2601, -3.0522]],
[[-1.5681, -1.5121, 0.1400],
[-3.5842, -1.0641, 0.9520],
[ 0.2800, -1.4841, 0.4760]],
[[-0.9240, -2.9961, -1.1761],
[-2.5481, -1.6801, -0.5600],
[-0.4760, -1.9321, 0.9800]],
[[ 0.5880, 0.7840, 0.7560],
[ 0.1960, 0.3640, 0.5600],
[ 0.9800, 0.3360, 0.7280]],
[[-1.3441, -0.1960, 0.5600],
[-2.0441, -1.0361, -1.9321],
[-0.9520, -0.5320, -1.4841]],
[[-3.0241, -2.0441, -1.7081],
[-0.0280, 0.9240, -2.4361],
[-0.1960, -0.1120, -2.4361]]]], size=(1, 8, 3, 3), dtype=torch.qint8,
quantization_scheme=torch.per_channel_affine,
scale=tensor([0.0280], dtype=torch.float64), zero_point=tensor([0]),
axis=0)), ('conv3.bias', None), ('conv3.scale', tensor(0.4081)), ('conv3.zero_point', tensor(111)), ('quant.scale', tensor([10.0395])), ('quant.zero_point', tensor([22]))])
Finally, I got quantized conv weight of first conv layer (convert to numpy) like:
[[[[-128 51 -69], [ 60 24 -68], [ -5 16 -65]]], [[[ 100 85 -113], [ -12 94 -128], [ 68 89 91]]], [[[ 32 -29 -55], [ -51 21 23], [-128 -48 98]]], [[[-128 -10 32], [ -31 7 91], [ 82 85 3]]], it can be easily computed from the float weight, scale and zero point.
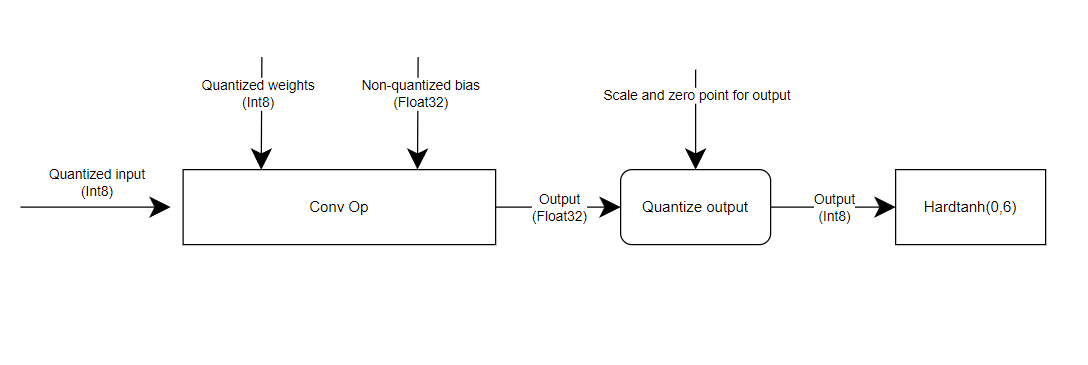
What confused is that we can see there is float bias value in first and the second fused conv layers, and I guess it’s comes from the progress of the operation which fusing the [conv, bn, relu].
Is that float bias in fused conv layer still behave same as the original nn.Conv2D ? ( In my opinion, all the value involve in inference process was in qint8, how is the float bias participate in calculations? );
What’s more, Does the (‘conv1.scale’, tensor(0.1366)), (‘conv1.zero_point’, tensor(0)) is the qparam of ReLU? How does it computed in fused model?
Thanks a lot there is any help.