C. Exponentially weighted moving average (EWMA) s(i) = a * x(i) + (1-a) * x(i-1)
where a is a smoothing factor set to 0.1 and s(0) = 27.527
s(0) = 27.527
s(1) = 25.825
s(2) = 23.808
D. Differently than above
Please also comment on the way validation loss is computed differently.
I would view A as the correct way of doing it and B as a (common) approximation. If the number of batches is large and the last error isn’t particularly off, it might not matter as much.
One thing to keep in mind is that during training, the loss is also changed (hopefully decreasing) by the updates. This makes, in my view, some sort of moving average, like exponentially weighted moving average a contender for C. Depending on how fast the decay is, the last batch behaviour may be a bit more touchy there. In validation, on the other hand, the there aren’t updates and so there isn’t that much reason to use a moving average scheme.
I don’t think that the loss calculation itself is inherently different for validation (it would defeat the purpose a bit, too), but note that the way the model operates (dropout, batch norm) may be different.
The other thing to keep in mind is that small batch size may have other implications, e.g. for batch norm, adaptive optimizers like adam etc. If you have doubts, it may be safer to drop the last batch.
I’ve included your suggestion about exponentially weighted moving average in the original post as the option C.
Don’t you think the final EWMA value i.e. s(2) = 23.808 is an overestimate when compared with the final epoch loss obtained from each other method (16.342 and 14.561)? Another issue could be finding an optimal value for the smoothing parameter a.
The vanilla version is not really good for very short sequences, and there is a commonly used scheme to deal with the beginning (where you keep a MA of the weight/batch size as well as the value and then you divide the two, sometimes dubbed debiasing).
While this has a lot of warts, it does serve the purpose of giving a meaningful estimate if we believe that the value changes over the course of the training.
No, the thing I had in mind as C is what is done e.g. in the optimizers or discussed (not quite as clearly as I would need to understand it) on the moving average wikipedia page, see the paragraph starting with It can also be calculated recursively without introducing the error ….
This isn’t the average over the entire dataset as it weights the later losses more than the former.
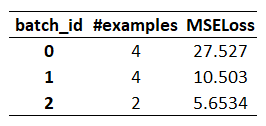
I just want to point out that there is small error in B. substitution. That confused me a little, so I actually checked it with the calculator. (27.527 + 10.503 + 5.6534*2) / total_batches: While the formula is correct, the multiplication by two in the numerator is wrong. Also, the result (14.5612) is correct.
If the multiplication by two would be correct, the result should have been 16.44.
So, the correct substitution is: (27.527 + 10.503 + 5.6534) / total_batches = (27.527 + 10.503 + 5.6534) / 3 = 14.5612