According to these links, I could understand that non-leaf variables’ gradients are not retained to save memory usage during backpropagation.
link 1
link 2
However, I still wonder How the memory saving method works.
Before asking the question precisely, please let me tell you my situation.
Currently, I am programming a simple deep learning framework for my project using CUDA/C++.
The model training structure of my framework is as follows:
Image1 Link
Which is really simple and directly implemented structure. I hope you understand this image easily.
Then, I started to compare the memory usage between my framework and Pytorch.
I tested ResNet50 model with ImageNet dataset.
(I guess I almost successfully implemented the structure of torchvision resnet50 model architecture in my framework.)
Relu inplace operation and nesterov momentum method is applied.
And this table is the comparison results:
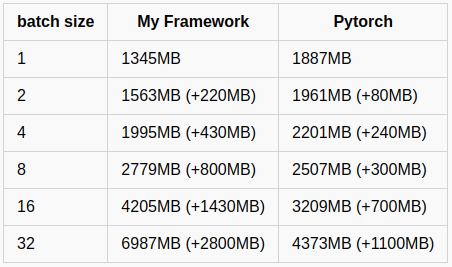
As you can see, the increasing memory size of My framework is almost twice bigger than Pytorch.
I tried to find out what makes such difference. Then, I found the fact that Pytorch reduces memory usage at the backpropagation by make intermediate buffer free as the links mentioned.
However, I still could not find How such memory saving method works in Pytorch.
Below image shows my guess on the memory saving technique.
At backpropagation, since the old gradient value is not necessary anymore, it can be freed.
To do so, making 2 shared buffer for input grad and output grad.
Then such buffer is used for temporarily saving and computing gradient values.
(I don’t think allocating and deleting GPU memory space at every backpropagation step is proper approach. Since frequently managing GPU memory can reduce hardware efficiency.)
Image2 link
I’m not sure if I guess the backpropagation workflow correctly.
I would be really appreciate if you teach me the magic of Pytorch backpropagation…