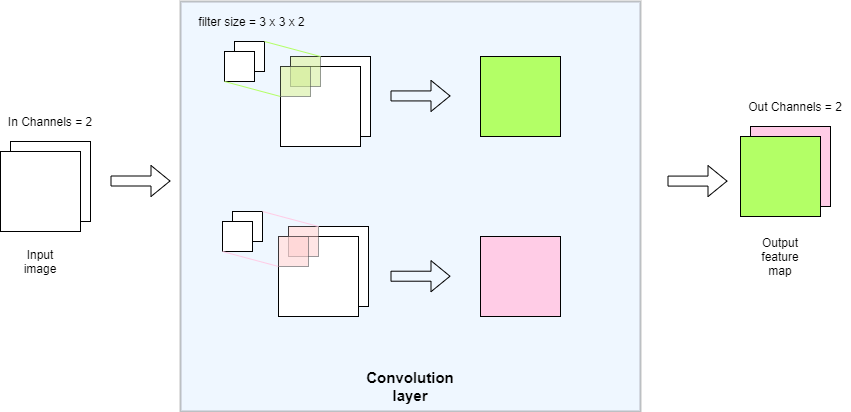
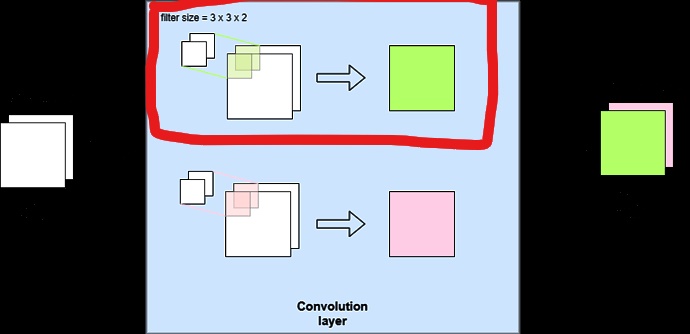
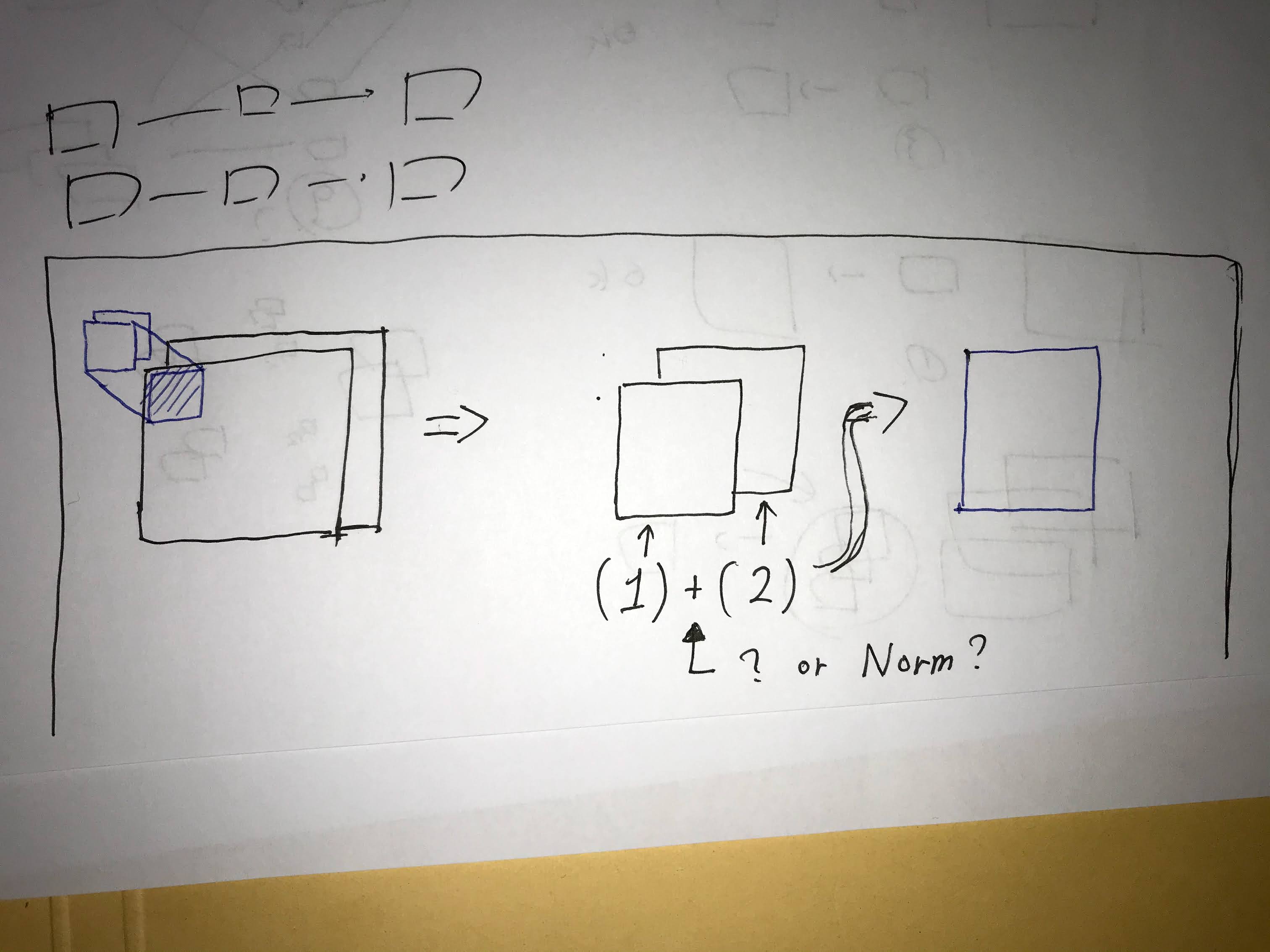
I couldn’t understand how many filters used in Conv2d.
This is my code, and please see the picuture.
At first I thought fig1 was correct, but when I looked at the code, fig2 seems to be correct.
Can someone give me a reference on this matter?
Thank you for reading to the last.
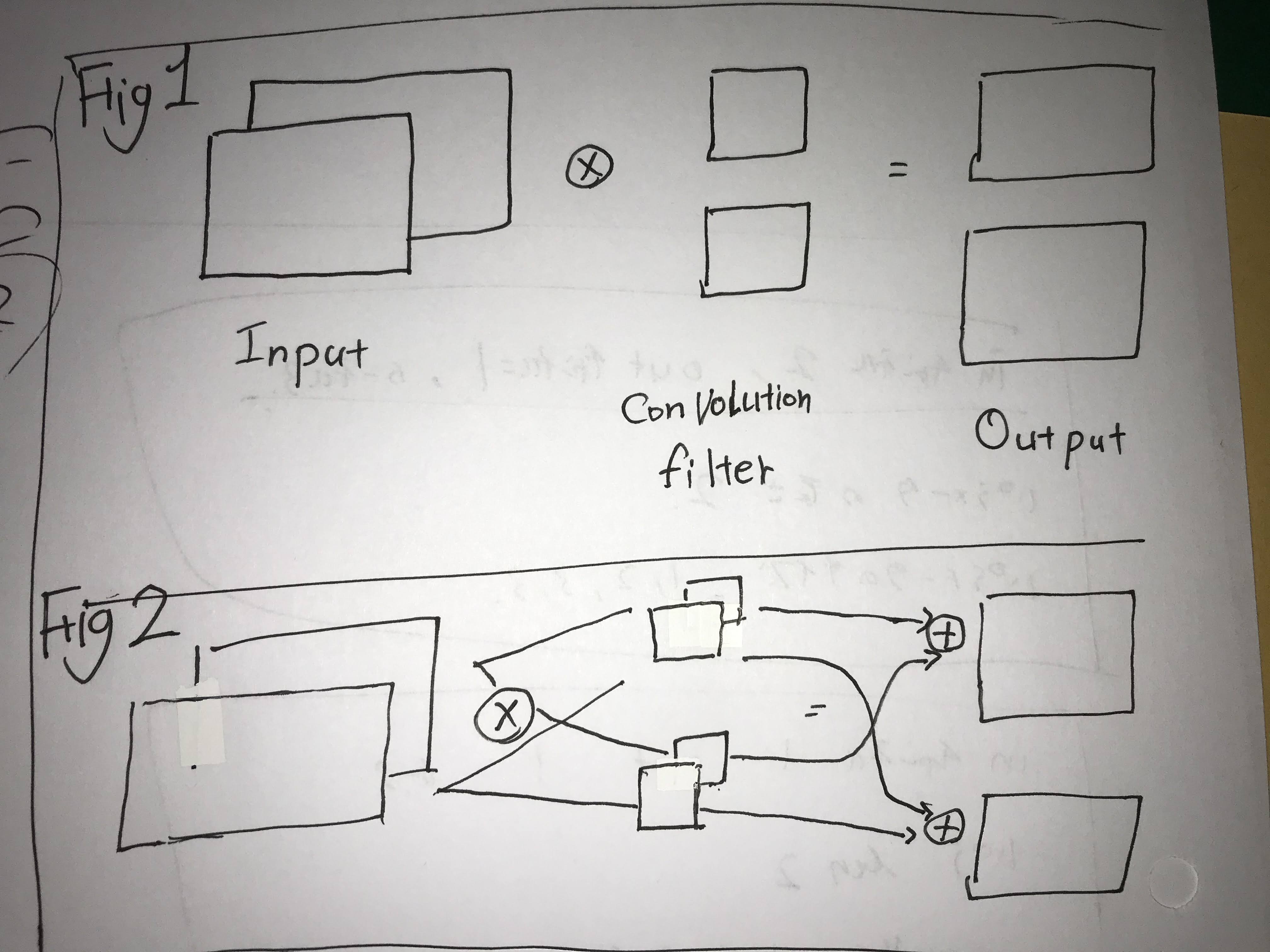
import torch.nn as nn
import torch
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels = 2, out_channels = 2, kernel_size = 3)
def forward(self, x):
x = self.conv1(x)
return x
net = Net()
print(net)
params = list(net.parameters())
print(params[0])
print(params[0].size())
======================================
~~ output on my colab, and I can see "4" (3*3)tensors. I thougt that are filters~~
Net(
(conv1): Conv2d(2, 2, kernel_size=(3, 3), stride=(1, 1))
)
Parameter containing:
tensor([[[[-0.1645, -0.2205, 0.0995],
[ 0.2017, -0.1659, 0.0161],
[ 0.0099, 0.1740, 0.0792]],
[[-0.1067, 0.1234, 0.0129],
[-0.1366, -0.0107, 0.0756],
[ 0.1778, -0.1056, 0.2191]]],
[[[-0.0351, 0.0904, -0.1394],
[-0.1006, 0.2080, 0.1312],
[-0.1741, -0.0246, -0.0775]],
[[-0.0482, -0.0906, -0.1982],
[ 0.2164, 0.0711, -0.0212],
[-0.0277, -0.0861, -0.1908]]]], requires_grad=True)