I tried to put checkpoint around transformer layer
like this
for layer in self.layers:
output, self_attn, encoder_attn = checkpoint(
layer, output, memory, tgt_mask, memory_mask, tgt_key_padding_mask, memory_key_padding_mask)
self_attns.append(self_attn)
encoder_attns.append(encoder_attn)
and around encoder/decoder modules like this
if self.training:
mel_outputs, gate_outputs = checkpoint(
self.decoder, mels_input, encoder_outputs, mels_attn_len_mask, texts_attn_len_mask)
decoder_self_attn, decoder_encoder_attn = None, None
else:
mel_outputs, gate_outputs, decoder_self_attn, decoder_encoder_attn = self.decoder(
mels_input, encoder_outputs, mels_attn_len_mask, texts_attn_len_mask)
With second approach, while more layers covered by checkpoint, model fail with 64 batch size.
Also I tried memory profiling, is it ok to have so much memoru use on backward?
Maybe im doing wrong something?
335 15.90M 18.00M 0.00B 0.00B for epoch in range(epoch_offset, hparams.epochs):
346 180.23M 246.00M 164.34M 228.00M for i, batch in enumerate(train_loader):
347 182.84M 310.00M 2.60M 64.00M x, y = parse_batch(batch)
348 433.07M 3.05G 250.23M 2.75G y_pred = model(x, y)
349 404.03M 532.00M -29.04M -2.53G loss, losses = criterion(x, y, y_pred)
361 404.03M 500.00M 0.00B 0.00B if hparams.fp16_run:
362 with amp.scale_loss(loss, optimizer) as scaled_loss:
363 scaled_loss.backward()
364 else:
365 14.43G 14.64G 14.03G 14.15G loss.backward()
Its turned out, im not sure why, batch size have great impact on model:
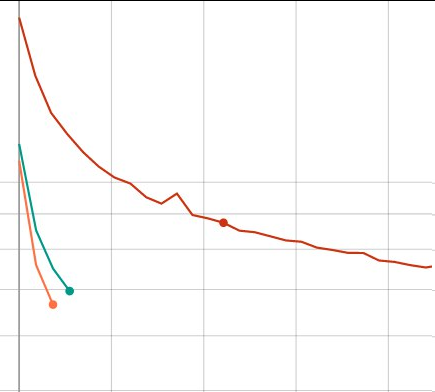
Batch size 32 64 and 76
So i want to maximize batch size with checkpointing, but cannot find guids how to do it right.