Hi. I’m currently working on a personal implementation of the Transformer architecture. The code I’ve written as here.
The problem that I’m facing is that I believe my model isn’t training properly and I’m not sure what kind of measures I should take to fix that. I’ve come to this conclusion after using Weights & Biases to visualize the model’s gradient histograms and they look something like this:
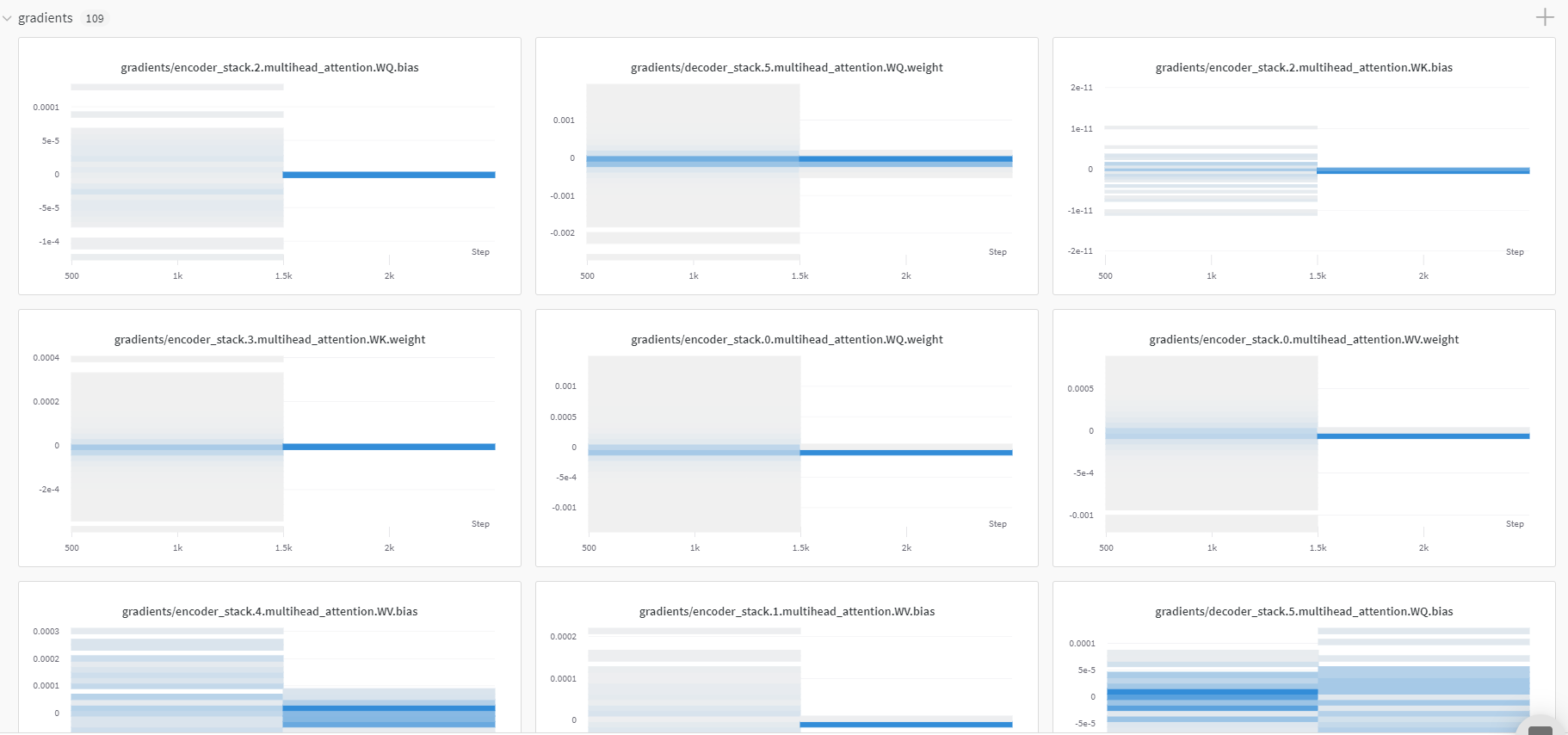
The gradients seem to quickly converge to zero. There is a portion of code that contains a feedforward neural network that uses ReLU activation, and I changed this to Leaky ReLU under the suspicion that dying ReLU’s may be the problem. However, using Leaky ReLU’s doesn’t help and just prolongs the zero-convergence.
Any feedback on what else I may try is appreciated.