Using the TorchRL framework and a collector, what should be the output of a rollout for traj_ids, done and next.done when an episode reaches a terminal state?
Considering a 6 steps rollout, I assume it should be as follows:
TensorDict({
"obs": torch.Tensor(...), # the observation at time t
"action": torch.Tensor(...), # the action at time t, based on the observation at time t
"done": torch.Tensor(...), # done state for "obs" at time t - should almost always be False (unless done at reset)
"next": TensorDict({
"obs": torch.Tensor(...), # the observation at time t+1, resulting from (obs, action) at time t
"reward": torch.Tensor(...), # the reward at time t+1, resulting from (obs, action) at time t
"done": torch.Tensor(...), # the done at time t+1, resulting from (obs, action) at time t - can be True when the transition is terminal
}, [...]),
}, [...])
Why a “done” state at the root? Just to catch the very rare cases where the reset() returns a state that is done.
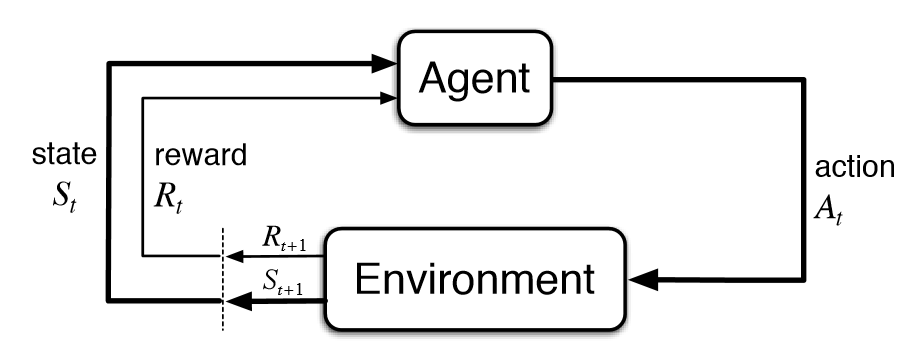
The decision on making reward / done belong to t+1 and action to t is based on the famous illustration from Sutton and Barto