Hi,
I am trying to build a face verification model using a siamese model on wikifaces dataset. Link to repo https://github.com/sriharsha0806/Face-Verification
I built a custom dataset and currently, when running train.py each epoch is taking too long. The dataset contains 2,24,800 images. I used only wiki faces which are 60,000 images in total. Still, it is taking more than 1-2 hours to complete each epoch. May I know what is the bug in the code or how to accelerate it?
Can you please post the output while training. Post the timing for each epoch also
for reference, I ran the experiment on my device with the below mentioned configurations
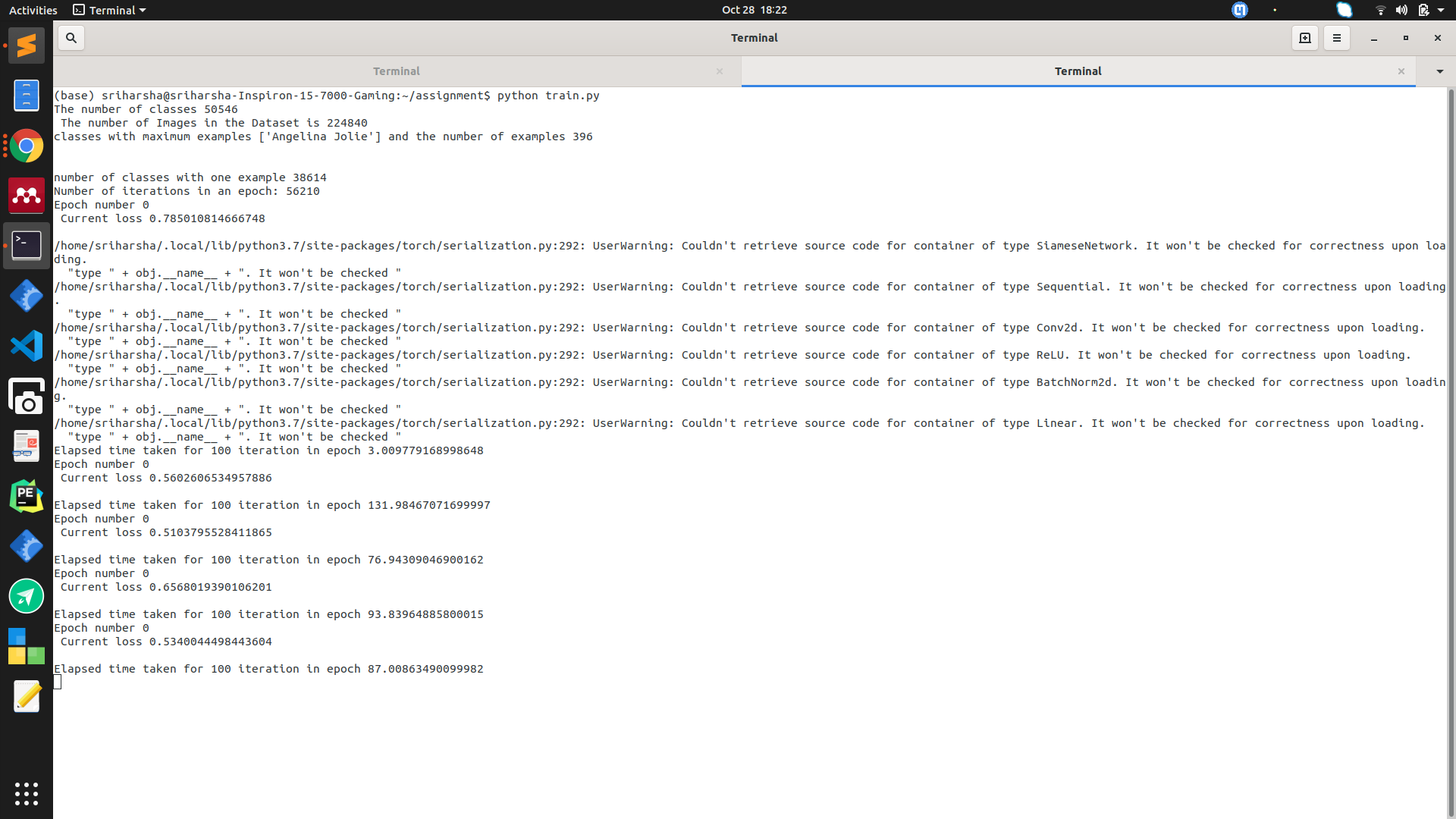
This is the output and time taken by 100 iterations in an each epoch. In each iteration, there are 4 examples.
Configuration of device: GTX970
batch_size = 4
number_of_workers = 4
Hello. Maybe the FC layers are clogging up a lot of time. Remove the fully connected layers and replace them with a AveragePooling layer
Hi, as @raghavendragaleppa mentioned try using a fully convolutional network or a larger batch size(4 seems too low). But I doubt batch_size could be a bottleneck given the FC layers size.
Hi, I am running main program with a batch size of 32
will try that but I think the main problem is with dataloader. I ran a dataiter
vis_dataloader = DataLoader(siamese_dataset,
shuffle=True,
num_workers=8,
batch_size=4)
from time import perf_counter
t1=perf_counter()
dataiter = iter(vis_dataloader)
example_batch = next(dataiter)
t2 = perf_counter()
concatenated = torch.cat((example_batch[0],example_batch[1]))
imshow(torchvision.utils.make_grid(concatenated))
print(example_batch[2].numpy())
It’s taking an average of 4s. In each epoch there are around 6000 iterations. I think this is where most of the time for code is elapsing. Anyway I will try out your idea and will let you.
@sriharsha0806
The num_workers=8 is a very high number if your CPU is not powerful enough and instead it will be an overhead, and besides num_worker doesn’t help much when your batch_size is low and you have less amount of augmentations going on. The dataloader works on CPU so keeping num_workers = 8 will be problematic if your CPU is not powerfull enough. Check the timing for each iteration for num_workers=1 and num_workers=0 and also check the timings by using pin_memory=True.
Also i can see that you have very less augmentation going on, so the problem must be in the dataloader itself. Reduce the num_workers to 1 and see how much each iteration takes.
Hi @raghavendragaleppa and @mailcorahul
Actually, I forgot to mention net.train() before training This is what causing the lag. I apologise for the mistake.