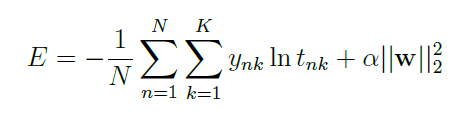Can someone give me a further example?
Thanks a lot!
BTW, I know that the latest version of TensorFlow can support dynamic graph.
But what is the difference of the dynamic graph between these two frameworks?
set “weight_decay” parameter to a non zero value in your optimizer(sgd, adam, …)(it’s the alpha in your equation)
edit: I think it’s alpha times two actually
I think I miss one row: def backward
Cuz ‘w’ is the weight. It is updated continuously by steps.
I just wonder if I need to do the grad-decent by myself?
have you seen this?
there are two ways to handle backprop, doing it by hand or using the autograd package (and also a third way which is using both of them, by defining backward)
if you are using the autograd, and your modules are composed of standard operations, you can simply define your loss without the L2 regularizer and in the optimizer define the regularizer
class custom(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x
net = custom()
optimizer = optim.SGD(net.parameters(), lr=0.01, weight_decay=0.01)
criterion = nn.MSELoss()
for batch in batches:
optimizer.zero_grad()
y = net(batch['x'])
loss = criterion(y, batch['y'])
loss.backward()
optimizer.step()
I use the 3 layers CNN net defined by myself with the nn.MSELoss() before. It’s autograd.
But now I want to compare the results if loss function with or without L2 regularization term.
If I use autograd nn.MSELoss(), I can not make sure if there is a regular term included or not.
p.s.:I checked that parameter ‘weight_decay’ in optim means “add a L2 regular term” to loss function.
Furthermore, if I want to add a “L1” norm term in my loss function, I CANNOT USE THE autograd ?
no, you can always use autograd (even if your function does not have a derivative, you can use something else as derivative and go backward from there), what i meant was that when you have simple functions, there is no need to write backward() yourself
adding L1 loss is simple:
loss = mse(pred, target)
l1 = 0
for p in net.parameters():
l1 = l1 + p.abs().sum()
loss = loss + lambda_l1 * l1
loss.backward()
optimizer.step()
in general loss of a network has some terms, adding L2 term via optimizer class is really easy and there is no need to explicitly add this term (optimizer does it), so if you want to compare networks, you can simply tune weight_decay
I want to follow an implementation of a Keras model in which only on some conv layers an l2 kernel_regularizer has been used. Now I have followed your implementation but am wondering if it suffices to filter for the names of the layers that I want to include my regularization on or not. I.e. along the lines of:
reg_lambda=0.01
l2_reg = 0
if isinstance(layer_names, list):
for W in self.model.named_parameters():
if "weight" in W[0]:
layer_name = W[0].replace(".weight", "")
if layer_name in layer_names:
l2_reg = l2_reg + W[1].norm(2)
loss = loss + l2_reg * reg_lambda
loss.backward()
How do you experiment with different values for weight_decay? So that you could show the amounts of regularization on the x axis and validation set performance on the y axis
I recently used this to add L2 regularization with LBFGS optimizer for a linear classification model
reg_loss = 0
for mod in self.model.modules():
if isinstance(mod, _BatchNorm):
if self.decay_bn:
for name, param in mod.named_parameters(recurse=False):
reg_loss = reg_loss + param.norm(2)
else:
for name, param in mod.named_parameters(recurse=False):
if not name.endswith("bias"):
reg_loss = reg_loss + param.norm(2)
else:
if self.decay_bias:
reg_loss = reg_loss + param.norm(2)