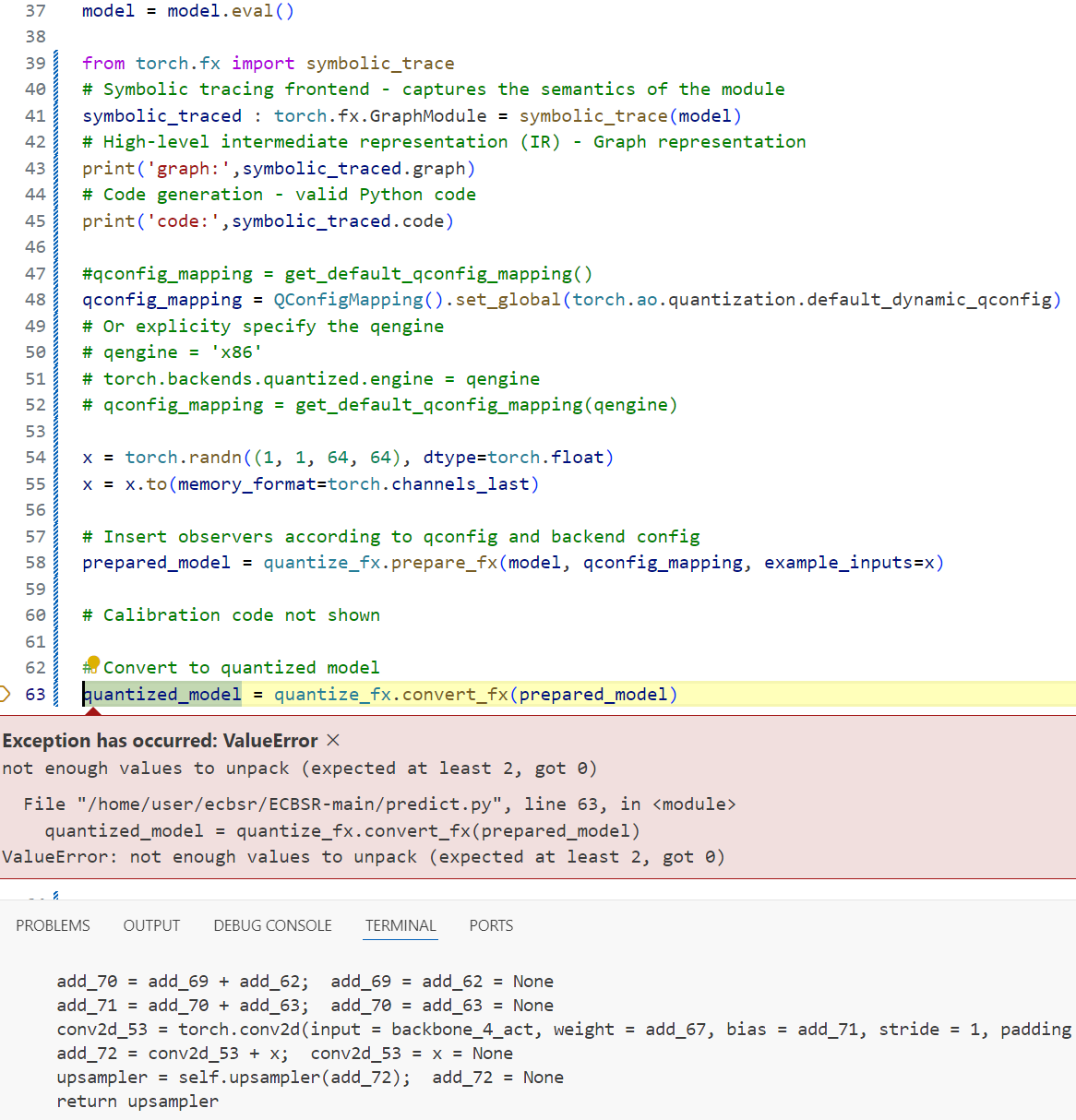
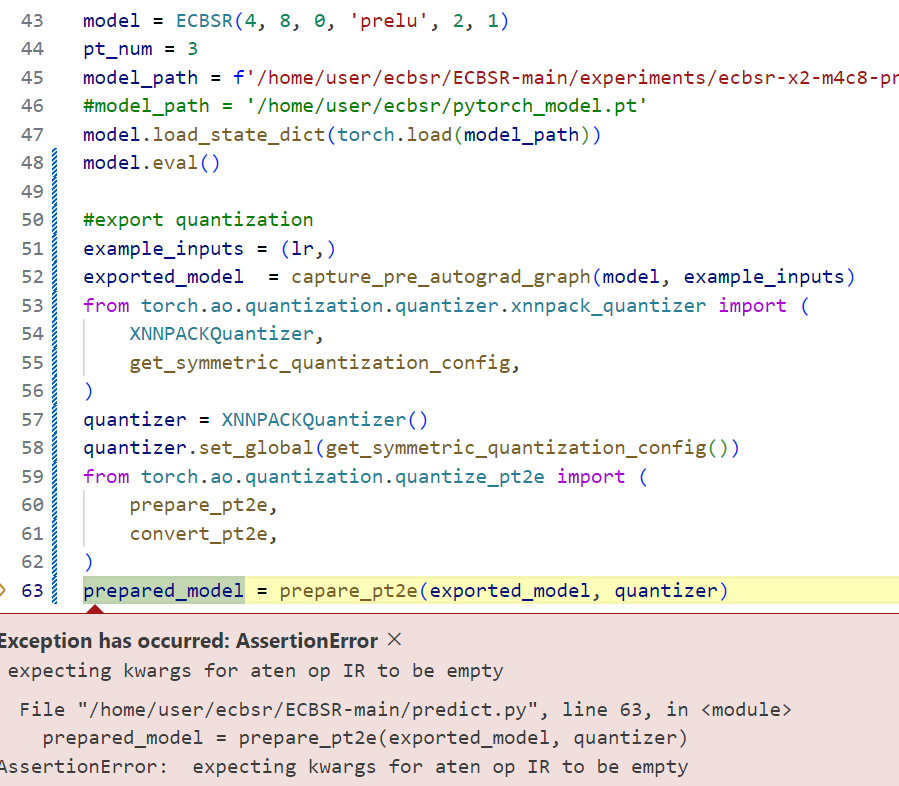
Based on the output of symbolic_traced.graph, I have adjusted the model to support symbol tracking. Now that the output of symbolic_traced.graph no longer reports errors, I need to verify what else is needed to ensure that the model can be quantified. What I mean is, the convert_fx() function reports the following error. How to adjust the model ?
from torch.ao.quantization import (
get_default_qconfig_mapping,
get_default_qat_qconfig_mapping,
QConfigMapping,
)
import torch.ao.quantization.quantize_fx as quantize_fx
In addition to the fx mode, I also tried the export mode,it reports errors as the picture above
AssertionError: expecting kwargs for aten op IR to be empty
This’s the full error,and my model contained nn.PixelShuffle,Is this operator supported ?
Traceback (most recent call last):
File “/home/user/ecbsr/ECBSR-main/predict.py”, line 63, in
prepared_model = prepare_pt2e(exported_model, quantizer)
File “/home/user/miniconda3/envs/ecbsr/lib/python3.9/site-packages/torch/ao/quantization/quantize_pt2e.py”, line 109, in prepare_pt2e
model = prepare(model, node_name_to_scope, is_qat=False)
File “/home/user/miniconda3/envs/ecbsr/lib/python3.9/site-packages/torch/ao/quantization/pt2e/prepare.py”, line 475, in prepare
_maybe_insert_input_and_output_observers_for_node(node, model, obs_or_fq_map, is_qat)
File “/home/user/miniconda3/envs/ecbsr/lib/python3.9/site-packages/torch/ao/quantization/pt2e/prepare.py”, line 416, in _maybe_insert_input_and_output_observers_for_node
_maybe_insert_input_observers_for_node(
File “/home/user/miniconda3/envs/ecbsr/lib/python3.9/site-packages/torch/ao/quantization/pt2e/prepare.py”, line 383, in _maybe_insert_input_observers_for_node
assert (
AssertionError: expecting kwargs for aten op IR to be empty
could you modify /home/user/miniconda3/envs/ecbsr/lib/python3.9/site-packages/torch/ao/quantization/pt2e/prepare.py to print what is the op? or just add a breakpoint there, it could help further identify the issue
assert (
node.target == torch.ops.aten.clone.default or
node.target == torch.ops.aten.zeros_like.default or
len(node.kwargs) == 0
), f" expecting kwargs for aten op IR to be empty | {node.target} | {node.kwargs}"
↑ I modified the source code and printed out the error message: expecting kwargs for aten op IR to be empty | aten.zeros.default | {‘device’: device(type=‘cpu’), ‘pin_memory’: False}
The following code has already been executed, otherwise the model inference would not have executed properly.My question is why there is little change in memory usage when quantifying. When I use Intel NNCF quantization, they point out that the reason is "NNCF does not support quantization of custom PyTorch modules with weights."Does PyTorch have similar restrictions?