Hello,
I’m not experienced in PyTorch very well and perhaps asking a weird question.
I’m running my PyTorch script in a docker container and I’m using GPU that has 48 GB.
Although it has a larger capacity, somehow PyTorch is only using smaller than 10GiB and causing the “CUDA out of memory” error.
Is there any method to let PyTorch use more GPU resources available?
I know I can decrease the batch size to avoid this issue, though I’m feeling it’s strange that PyTorch can’t reserve more memory, given that there’s plenty size of GPU.
RuntimeError: CUDA out of memory. Tried to allocate 124.00 MiB (GPU 0; 47.51 GiB total capacity; 9.21 GiB already allocated; 15.06 MiB free; 9.74 GiB reserved in total by PyTorch)
And I noticed that even after reducing the batch size, I still encounter the problem at the second epoch (not while the first mini-batch iteration).
And I confirmed that I’m not trying to save the list of models or the list of losses themselves. (Saving loss.item() as a list instead)
Is it probably because the accumulated gradient graph is exploding in size and it’s unavoidable?
I tried torch.cuda.empty_cache() too but it didn’t help in my case.
Does the issue go away if you run the same process on the machine directly (as opposed to running it inside the Docker container?) In that case, it could be due to some kind of Docker (or Docker + CUDA) limitation. I’ve run into this before and couldn’t find an easy fix online, but you might be well served to also ask the same question on a Docker forum.
Regardless, if the batch size is part of what’s hogging memory, you could give this project a try. With 1.6k stars on Github, it looks promising, though I cannot confirm whether it works.
Could you check if other processes are using the device and are allocating memory via nvidia-smi?
Also, make sure that torch.cuda.set_per_process_memory_fraction(fraction, device=None) is not set somewhere in your script.
Thank you for your comment, actually, I have been avoiding running the code on the machine directly and I don’t have an equivalent environment that I have inside the container.
But yes, it seems to be a Docker problem and I may not understand how the container allocates and limits the memory usage correctly.
I will look into the provided link too, thank you!
Hi ptrblck,
Thank you for your comment.
I’m not setting torch.cuda.set_per_process_memory_fraction(fraction, device=None) in my script.
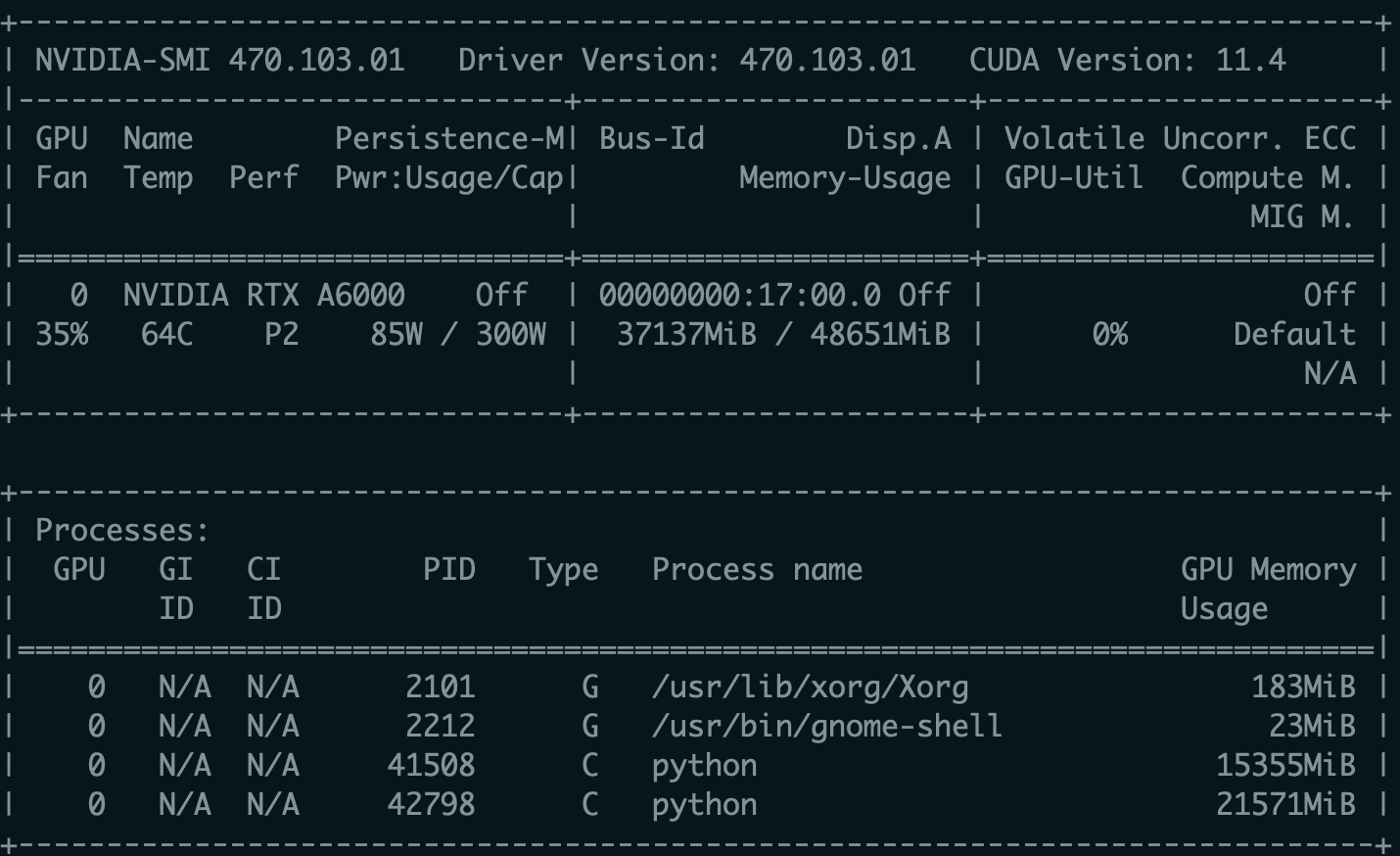
And here’s the result of nvidia-smi:
And actually, I have some other containers that are not running any scripts now.
I thought each docker container can fully utilize the GPU resource when the GPU-Util is 0%, but at the same time I find in the last row it says that about 36GB of GPU is already in-use.
Does this probably mean even if the other containers are not using GPU to run scripts currently, each container automatically limits its maximum GPU resource reserved if there’re multiple containers?
No, docker containers are not limiting the GPU resources (there might be options to do so, but I’m unaware of these).
As you can see in the output of nvidia-smi 4 processes are using the device where the Python scripts are taking the majority of the GPU memory so the OOM error would be expected.
The “GPU-Util.” shows the percentage of the kernel execution time in the last time frame, i.e. it’s showing the compute resource usage not the memory usage.
Thank you for your insight.
Then I was misunderstanding the output of nvidia-smi.
I will find and kill the processes that are using huge resources and confirm if PyTorch can reserve larger GPU memory.
→I confirmed that both of the processes using the large resources are in the same docker container. As I was no longer running scripts in that container, I feel it was strange. Anyway, I killed the processes and I’m running my code again to check if I still encounter the issue or not.
It seems to be working w/o causing the OOM error. I’m not sure why the container no longer running scripts was occupying huge GPU memory, but once I killed these processes, I no longer encountered the problem.
Thank you both for providing me with the insights!
FYI: I have confirmed that the process that had been terminated with Ctrl+Z was occupying memory. I sometimes use the command when Ctrl+C doesn’t work and this was the reason. This was solved by deleting the Docker container.
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 2.15 GiB. GPU 0 has a total capacty of 11.72 GiB of which 826.50 MiB is free. Including non-PyTorch memory, this process has 10.91 GiB memory in use. Of the allocated memory 7.67 GiB is allocated by PyTorch, and 3.03 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
<user>@<machine>whisper-finetuning(main)$ nvidia-smi
Wed Nov 22 00:24:40 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.129.03 Driver Version: 535.129.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4070 On | 00000000:01:00.0 Off | N/A |
| 30% 36C P8 10W / 200W | 2MiB / 12282MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
Looks like before running the process I have a lot of GPU memory, but PyTorch reserve 3.03 GiB but do not allocate it …
@ptrblck Do you know how to fix it ? Could you help with it ?