HJX-zhanS
July 20, 2022, 2:15am
1
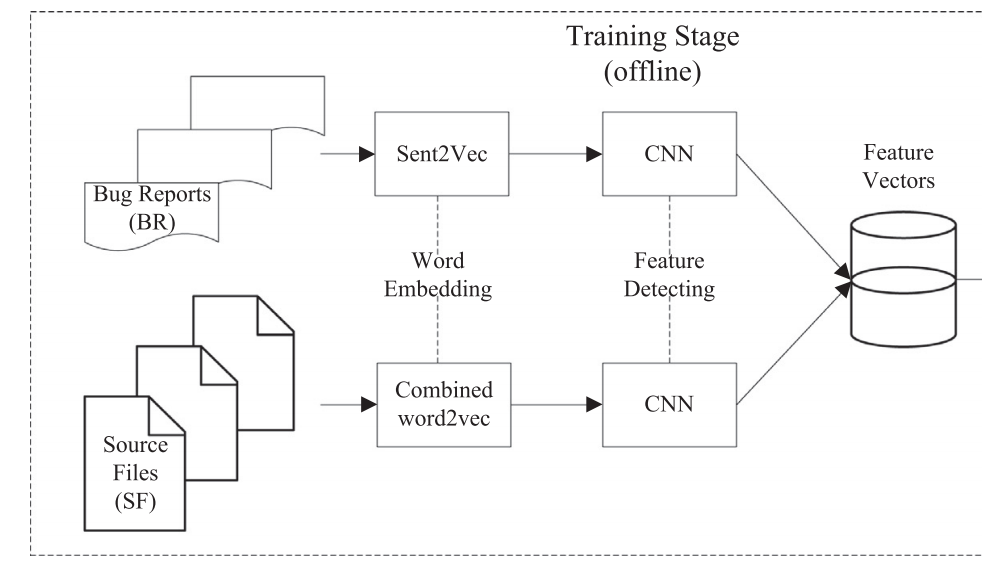
I am currently trying to build the following model.
My code is as following shows:
class CNN_1(torch.nn.Module):
def __init__(self):
super(CNN_1, self).__init__()
...
def forward(self, X):
...
return X
class CNN_2(torch.nn.Module):
def __init__(self):
super(CNN_2, self).__init__()
...
def forward(self, X):
...
return X
class CNN_3(torch.nn.Module):
def __init__(self):
super(CNN_3, self).__init__()
self.cnn1 = CNN_1()
self.cnn2 = CNN_2()
self.fc=torch.nn.Linear(... , ...)
def forward(self, X_1, X_2):
X_1 = self.cnn1(X_1)
X_2 = self.cnn2(X_2)
X = torch.cat([X_1, X_2])
X = self.fc(X)
return X
The training code is as follows:
model = CNN_3()
criterion = CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
X_1 = ...
X_2 = ...
labe l= ...
model.train()
preds = model(X_1, X_2)
loss = criterion(preds, label)
loss.requires_grad_(True)
optimizer.zero_grad()
loss.backward()
optimizer.step()
However, the performance of the model is not good. I checked the parameters of the model before and after training, and found that after training, the model parameters did not change, and grad_value is None.
I don’t know what’s wrong, please help me, thank you.
thecho7
July 20, 2022, 2:22am
2
The structure is correct.optimizer.step() is correctly called?
This is the basic of how your model is updated.
optimizer.zero_grad()
out = model(input)
loss = loss_function(out, gt)
loss.backward()
optimizer.step()
1 Like
HJX-zhanS
July 20, 2022, 2:28am
3
Thank you for your answer.
The optimizer.step() is correctly called. But the model parameters did not change, and grad_value is None.
thecho7
July 20, 2022, 2:35am
4
Would you give us a code snippet?
HJX-zhanS
July 20, 2022, 2:45am
5
Here is the code snippet.
class ConvBlock(torch.nn.Module):
def __init__(self, kernel_h, emb_size, max_line):
super(ConvBlock, self).__init__()
self.cnn = torch.nn.Conv1d(in_channels=emb_size, out_channels=10, kernel_size=kernel_h)
self.max_pool = torch.nn.MaxPool1d(kernel_size=(max_line - kernel_h + 1))
def forward(self, X):
X = self.cnn(X.squeeze(1).permute(0, 2, 1))
X = F.relu(X)
# X = X.squeeze(-1)
X = self.max_pool(X)
X = X.squeeze(-1)
return X
class MyTextCNN(torch.nn.Module):
def __init__(self, emb_size, max_line):
super(MyTextCNN, self).__init__()
self.block2 = ConvBlock(3, emb_size, max_line)
self.block3 = ConvBlock(4, emb_size, max_line)
self.block4 = ConvBlock(5, emb_size, max_line)
def forward(self, X):
X = X.unsqueeze(1)
X_2 = self.block2(X)
X_3 = self.block3(X)
X_4 = self.block4(X)
X = torch.cat([X_2, X_3, X_4], dim=1)
return X
class AssembleModel(torch.nn.Module):
def __init__(self):
super(AssembleModel, self).__init__()
self.cnn_1 = MyTextCNN(300, 200)
self.cnn_2 = MyTextCNN(300, 500)
self.fc = torch.nn.Linear(30, 2)
def forward(self, X_1, X_2):
X_1 = self.cnn_1(X_1)
X_2 = self.cnn_2(X_2)
X = torch.cat([X_1, X_2], dim=1)
out = self.fc(X)
return out
# train
model = AssembleModel()
criterion = CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
X_1 = ...
X_2 = ...
label= ...
model.train()
optimizer.zero_grad()
preds = model(X_1, X_2)
loss = criterion(preds, label)
loss.requires_grad_(True)
loss.backward()
optimizer.step()
HJX-zhanS
July 20, 2022, 5:10am
7
I use this code to check grad_value:
for name, parms in model.named_parameters():
print('-->name:', name)
print('-->para:', parms)
print('-->grad_requirs:', parms.requires_grad)
print('-->grad_value:', parms.grad)
As for loss.requires_grad_(True), if I remove it, I get this error:
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
I don’t see any operation which would detach the computation graph, so could you post the input shapes to make the code executable?
HJX-zhanS
July 20, 2022, 6:06am
9
The shape of X_1 is (batch_size, 200, 300), the shape of X_2 is (batch_size, 500, 300).
Thanks! The shapes don’t work as you would be running into a shape mismatch in self.fc After fixing it by setting in_features=60 the model works correctly:
model = AssembleModel()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-3)
X_1 = torch.randn(10, 200, 300)
X_2 = torch.randn(10, 500, 300)
label = torch.randint(0, 2, (10,))
model.train()
optimizer.zero_grad()
preds = model(X_1, X_2)
loss = criterion(preds, label)
loss.backward()
optimizer.step()
for name, param in model.named_parameters():
print(name, param.grad.abs().sum())
Output:
cnn_1.block2.cnn.weight tensor(81.9196)
cnn_1.block2.cnn.bias tensor(0.0434)
cnn_1.block3.cnn.weight tensor(119.6594)
cnn_1.block3.cnn.bias tensor(0.0476)
cnn_1.block4.cnn.weight tensor(126.1779)
cnn_1.block4.cnn.bias tensor(0.0402)
cnn_2.block2.cnn.weight tensor(132.8887)
cnn_2.block2.cnn.bias tensor(0.0697)
cnn_2.block3.cnn.weight tensor(106.3185)
cnn_2.block3.cnn.bias tensor(0.0431)
cnn_2.block4.cnn.weight tensor(169.7578)
cnn_2.block4.cnn.bias tensor(0.0539)
fc.weight tensor(10.4102)
fc.bias tensor(0.1133)
So your actual use case seems to use another code.
1 Like
HJX-zhanS
July 20, 2022, 8:51am
11
Thank you so much! I tested the code you provided and succeeded.