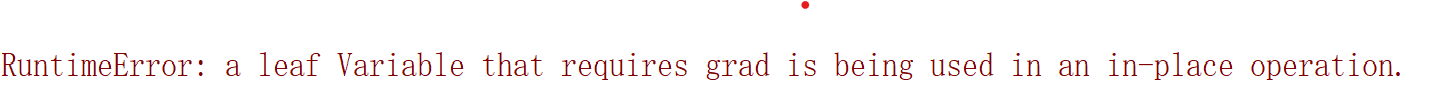I try like this , it didn’t report bug, but the value of parameter is not changed.
But using torch.nn.init.xavier_normal_(model_0.state_dict()[‘classifier.weight’]) , it works, why?
I try like this , it didn’t report bug, but the value of parameter is not changed.
But using torch.nn.init.xavier_normal_(model_0.state_dict()[‘classifier.weight’]) , it works, why?
Also, I try to use named_parameter to select the parameter I want to initialize:
But when I use: v.data=regression_fc.data It works.
Why? What’s the difference between v=regression_fc and v.data=regression_fc.data ?
I alsways assign value to Variable by simply using variable=xxx , when should I need to add .data?
You could modify the state_dict and reload it afterwards:
state_dict = model.state_dict()
state_dict['classifier.weight'] = torch.randn(10, 10)
model.load_state_dict(state_dict)
Also, if you are using the loop over named_parameters, make sure to manipulate the parameters inplace and with a torch.no_grad() guard:
with torch.no_grad():
for name, param in model.named_parameters():
if 'classifier.weight' in name:
param.copy_(torch.randn(10, 10))
I wouldn’t recommend the usage of the .data attribute, as Autograd cannot track this operations and you might create silent bugs in your code.
How about something like:
model.classifier.weight = torch.nn.Parameter(torch.randn(10, 10))
Could this work @ptrblck? Modifying the state_dict and reloading it essentially gives the same torch size mismatch error.
Your approach could work, if you want to change the parameter of the model instead of the state_dict.
That should not be the case, if you make sure the parameter in the state_dict has the same shape as the parameter in the model.
The parameter in the state_dict that I’m trying to load is from a checkpoint where the classifier.weight and classifier.bias have different Tensor sizes from those of the model. I think that’s why it doesn’t work?
size mismatch for classifier.bias: copying a param with shape torch.Size([42]) from checkpoint, the shape in current model is torch.Size([1000]).
Manipulating the state_dict works for me:
class MyModelA(nn.Module):
def __init__(self):
super(MyModelA, self).__init__()
self.lin = nn.Linear(10, 10)
self.classifier = nn.Linear(10, 42)
def forward(self, x):
x = F.relu(self.lin(x))
x = self.classifier(x)
return x
class MyModelB(nn.Module):
def __init__(self):
super(MyModelB, self).__init__()
self.lin = nn.Linear(10, 10)
self.classifier = nn.Linear(10, 1000)
def forward(self, x):
x = F.relu(self.lin(x))
x = self.classifier(x)
return x
modelA = MyModelA()
modelB = MyModelB()
sd = modelA.state_dict()
modelB.load_state_dict(sd) # your error
# replace tensors creating the shape mismatch with random tensors
sd['classifier.weight'] = torch.randn(1000, 10)
sd['classifier.bias'] = torch.randn(1000)
modelB.load_state_dict(sd) # works
What if this is not what I want? I mean, if I want to give the model’s parameter a new one with a different shape. How could I do it?
You can manually assign the new parameter to the model’s parameter:
lin = nn.Linear(10, 10, bias=False)
print(lin)
> Linear(in_features=10, out_features=10, bias=False)
x = torch.randn(1, 10)
out = lin(x)
print(out.shape)
> torch.Size([1, 10])
with torch.no_grad():
lin.weight = nn.Parameter(torch.randn(1, 10)) # out_features, in_features
out = lin(x)
print(out.shape)
> torch.Size([1, 1])
print(lin) # wrong information
> Linear(in_features=10, out_features=10, bias=False)
but note that the attributes won’t be automatically changes as well, so you might want to change them also manually.
Thank you for the answer.
What should I do instead if I wish to backprop through the variables which I have copied to the param? i.e. without using “torch.no_grad()”?
In
model.classifier.weight = torch.nn.Parameter(torch.randn(10, 10))
Should we assign it torch.no_grad() block? If we do it, would model.classifier.weight still have requires_grad = true?.
I tried it it dosent work for some reason
Do you see some errors when using this approach or unexpected results?
This question is really interesting! I am also working on the similar things. But I find another problem when using the function “copy_” (also other functions like “set_” with “_” at the end).
param.set_(param.data - lr * (a number))
It will bring an error:
PyTorch rightfully raises the error since inplace operations on leaf variables are disallowed in a differentiable context. Using the deprecated .data attribute will skip valid checks and you should wrap the inplace operation into a with torch.no_grad() context instead.