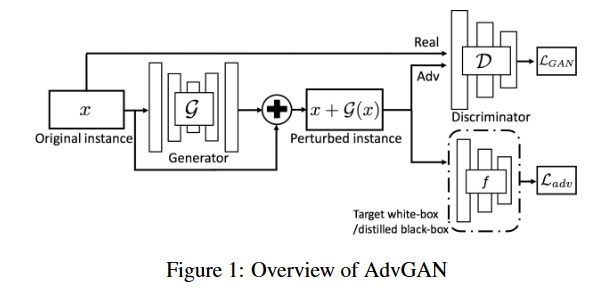
In the process of training a GAN, I am trying to change the params of gen() such that a cross-entropy loss: f_loss = CE_loss(f_pred, labels) is maximized and a different type of loss: lossG = torch.mean(torch.log(1. - output)) is minimized.
This is my code:
adv_ex = adv_ex.reshape(32, 28*28)
output = disc(adv_ex) #discriminator decides if advex is real or fake
lossG = torch.mean(torch.log(1. - output)) #get loss for gen's desired desc pred
adv_ex = adv_ex.reshape(-1,1,28,28)
f_pred = target(adv_ex) #.size() = [32, 10]
f_loss = CE_loss(f_pred, labels) #add loss for gens desired f pred
print(f_loss)
loss_G_Final = f_loss+lossG # can change the weight of this loss term later
opt_gen.zero_grad()
loss_G_Final = loss_G_Final.to(device)
loss_G_Final.backward()
opt_gen.step()
I’m pretty sure that this will minimize lossG, but also minimize f_loss. How can I change this so that the gen() parameters will maximize the crossentropy f_loss as well as minimize lossG?
here is the entire code block if needed:
# set up the optimizers and loss for the models
opt_disc = optim.Adam(disc.parameters(), lr=lr)
opt_gen = optim.Adam(gen.parameters(), lr=lr)
CE_loss = nn.CrossEntropyLoss()
for epoch in range(num_epochs):
for batch_idx, (real, labels) in enumerate(loader):
#get a fixed input batch to display gen output
if batch_idx == 0:
if epoch == 0:
fixed_input = real.view(-1,784).to(device)
adv_ex = real.clone().reshape(-1,784).to(device) # [32, 784] advex copy of first batch flattened
real = real.view(-1, 784).to(device) # [32, 784] # real batch flattened
labels = labels.to(device) # size() [32] 32 labels in batch
#purturb each image in adv_ex
tmp_adv_ex = []
for idx, item in enumerate(adv_ex):
purturbation = gen(adv_ex[idx])
tmp_adv_ex.append(adv_ex[idx] + purturbation)
adv_ex = torch.cat(tmp_adv_ex, dim=0)
# Train Generator: min log(1 - D(G(z))) <-> max log(D(G(z))
# also max the CE loss between target-model pred and true labels
adv_ex = adv_ex.reshape(32, 28*28)
output = disc(adv_ex) #discriminator decides if advex is real or fake
lossG = torch.mean(torch.log(1. - output)) #get loss for gen's desired desc pred
adv_ex = adv_ex.reshape(-1,1,28,28)
f_pred = target(adv_ex) #.size() = [32, 10]
f_loss = CE_loss(f_pred, labels) #add loss for gens desired f pred
print(f_loss)
loss_G_Final = f_loss+lossG # can change the weight of this loss term later
opt_gen.zero_grad()
loss_G_Final = loss_G_Final.to(device)
loss_G_Final.backward()
opt_gen.step()
# Train Discriminator: max log(D(x)) + log(1 - D(G(z)))
adv_ex = adv_ex.reshape(32, 784)
disc_real = disc(real).view(-1)
disc_fake = disc(adv_ex).view(-1)
lossD = -torch.mean(torch.log(disc(real)) + torch.log(1. - disc(adv_ex)))
opt_disc.zero_grad()
lossD.backward()
opt_disc.step()