I’m trying to build a synthesizer network that outputs the weights and biases of another network, given some input-output examples. The examples are generated by a reference network and the idea is to train a synthesizer that can infer the reference distribution.
Here’s a diagram that shows how the component networks are connected:
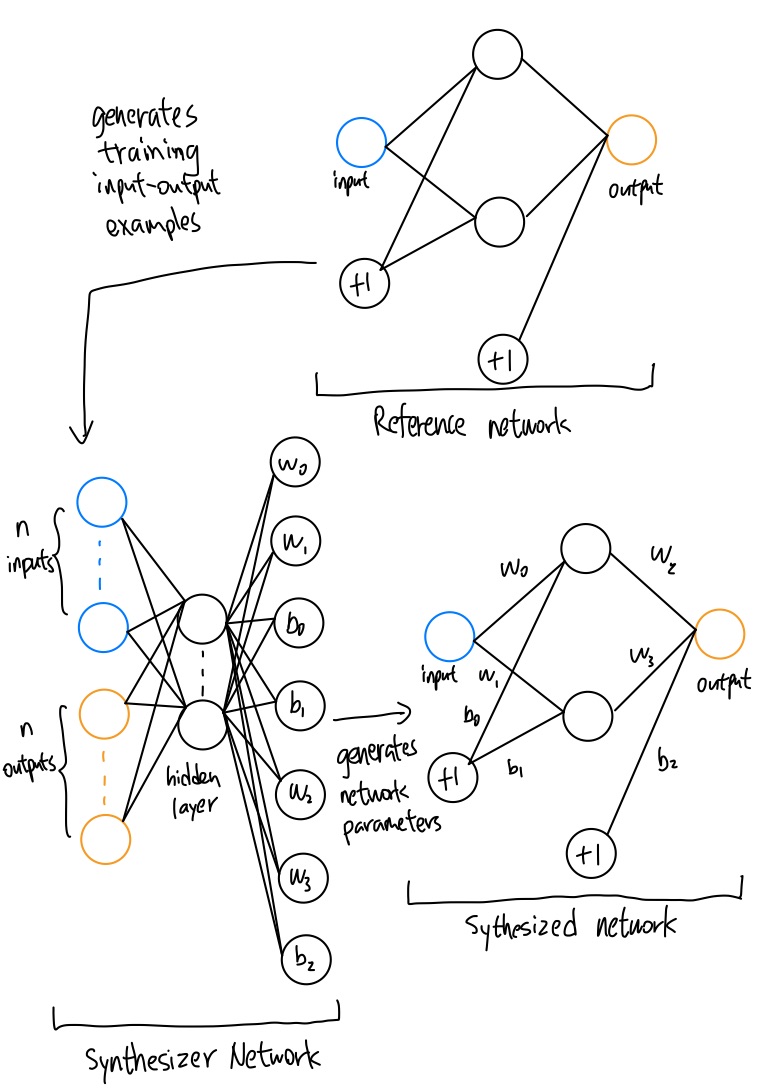
The challenge lies in how to perform backpropagation from the synthesized network through the synthesizer. I can’t find a way to fill in that gap between the synthesizer and synthesized networks during backpropagation. My current attempt that fails with the message:
---> ref_net.fc1.weight.set_(nn.Parameter(pred_net[:, 0:2].view(2, 1)))
ref_net.fc1.bias.set_(nn.Parameter(pred_net[:, 2:4]))
ref_net.fc2.weight.set_(nn.Parameter(pred_net[:, 4:6].view(1, 2)))
RuntimeError: a leaf Variable that requires grad is being used in an in-place operation.
I tried other variants besides set_ like direct assignments of the weights and biases. However, they all cut off the backpropagation process such that training cannot proceed and the loss remains constant. Here’s the entire code snippet:
NUM_EXAMPLES = 10
RANGE = 10
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class ReferenceNet(nn.Module):
def __init__(self):
super(ReferenceNet, self).__init__()
self.fc1 = nn.Linear(1, 2, bias=True) # First layer: 1 input, 2 hidden nodes
self.fc2 = nn.Linear(2, 1, bias=True) # Second layer: 2 hidden nodes, 1 output
def forward(self, x):
x = F.relu(self.fc1(x)) # ReLU activation on the first layer
x = self.fc2(x) # No activation on the output layer
return x
# Instantiate the test network
ref_net = ReferenceNet()
# Initialize weights randomly (this is done by default in PyTorch but shown here explicitly for clarity)
for param in ref_net.parameters():
nn.init.normal_(param, mean=0.0, std=0.1)
class SynthesizerNet(nn.Module):
def __init__(self):
super(SynthesizerNet, self).__init__()
self.fc1 = nn.Linear(NUM_EXAMPLES * 2, NUM_EXAMPLES * 1)
self.fc2 = nn.Linear(NUM_EXAMPLES * 1, 7)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# Instantiate the reason network
syn_net = SynthesizerNet()
# Training loop
optimizer = optim.Adam(syn_net.parameters(), lr=0.001)
criterion = nn.MSELoss()
# Create random input-output pairs from ReferenceNet
inputs = torch.rand(NUM_EXAMPLES, 1) * RANGE * 2 - RANGE
print(f"inputs.shape: {inputs.shape}")
with torch.no_grad():
outputs = ref_net(inputs)
print(f"outputs.shape: {outputs.shape}")
# Prepare data by concatenating inputs and outputs into a flat vector
train_data = torch.cat((inputs, outputs), dim=0)
print(f"train_data.shape: {train_data.shape}")
# Re-initialize reference network for training
ref_net = ReferenceNet()
print(f"outputs: {outputs}")
for epoch in range(500):
optimizer.zero_grad()
# synthesize a network based on input output pairs
pred_net = syn_net(train_data.view(1, NUM_EXAMPLES * 2))
print(f"pred_net: {pred_net}")
# set the weights of the reference network to the synthesized network
ref_net.fc1.weight.set_(nn.Parameter(pred_net[:, 0:2].view(2, 1)))
ref_net.fc1.bias.set_(nn.Parameter(pred_net[:, 2:4]))
ref_net.fc2.weight.set_(nn.Parameter(pred_net[:, 4:6].view(1, 2)))
ref_net.fc2.bias.set_(nn.Parameter(pred_net[:, 6:7]))
inputs = train_data[:NUM_EXAMPLES].view(NUM_EXAMPLES, 1)
outputs_pred = ref_net(inputs)
print("outputs_pred: ", outputs_pred)
loss = criterion(outputs, outputs_pred)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/500], Loss: {loss.item():.4f}')