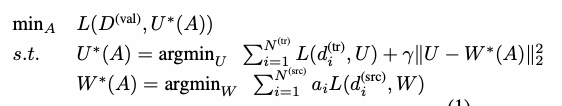The formula in the screenshot is what I want to implement.
Basically, there are two models U and W.
- we train the W on source data, then we multiply a trainable a to the loss and update the weights.
- we train the U on training data, then we add the loss to the l2 norm of the “distance between U’s weight and W’s weight”, and update the U.
- we update the trainable a by minimizing the loss of U on the validation dataset.
Therefore, to optimize the trainable a, we need three steps. It is like a meta-learning problem, so I tried higher library. However, I got the problem that I cannot optimize the “a”, because it seems that l2 norm of “distance between U and W” is not on the computation graph. Is there any way to fix this problem? Also I wonder does the algorithm make sense? Thanks!