Hi. I have an architecture based on an autoencoder (AE) and a discriminator (D) (see image below). I have an MSE reconstruction loss and CE classification loss. I want to train the AE to minimize the reconstruction (MSE) loss and maximise the classification (CE) loss while training the discriminator to get better in the classification - hence minimizing the CE over discriminator (D).
Hence I want to backpropagate CEloss over discriminator and (MSEloss - CEloss) over autoencoder.
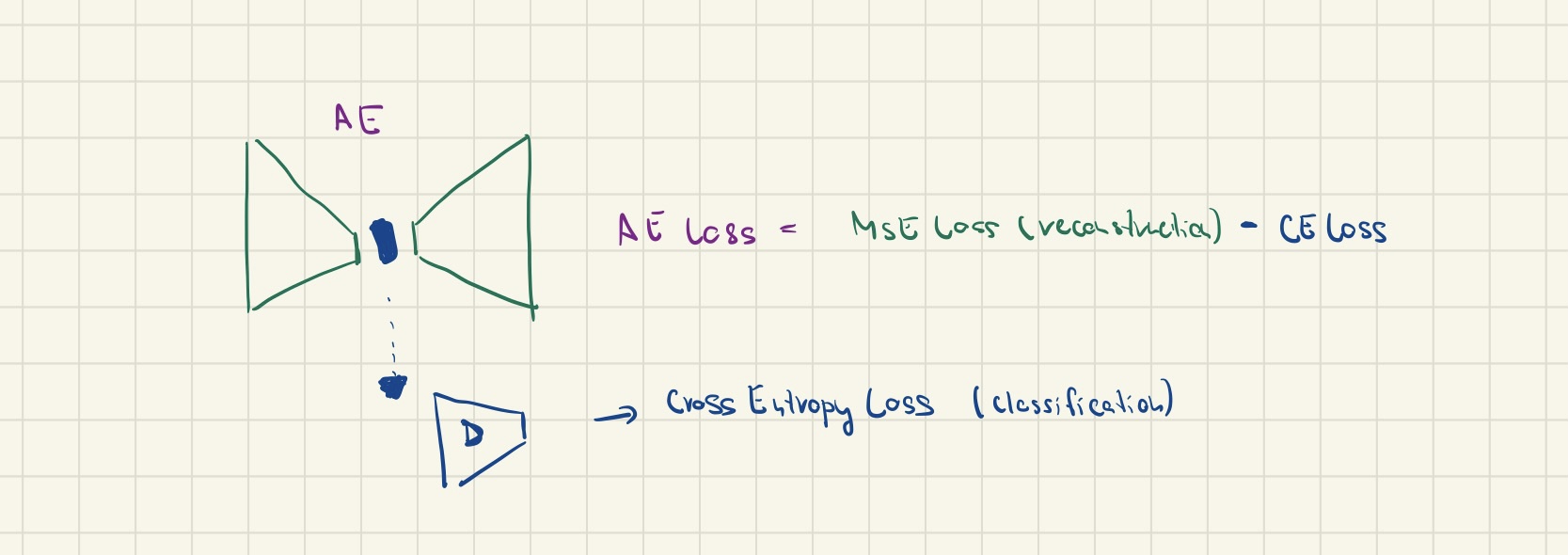
What is the correct way to do this?
Currently, I have this (code below) but at loss_ae.backward() I have the following error: RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [64]] is at version 2; expected version 1 instead.
input, true_class = data
optim_ae = AdamW(AEmodel.parameters(), lr1)
optim_d = AdamW(Dmodel.parameters(), lr2)
reconstruction, latent = AEmodel(input)
loss_mse = nn.MSELoss(reconstruction, input)
pred = DModel(latent)
loss_ce = nn.CrossEntropyLoss(pred, true_class)
loss_ae = loss_mse - loss_ce
optim_d.zero_grad()
loss_ce.bacward(retain_graph=True)
optim_d.step()
optim_ae.zero_grad()
loss_ae.backward()
optim_ae.step()