The error is as follows:
“RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [128, 4]], which is output 0 of TBackward, is at version 106; expected version 105 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True)”.
It depends on what do you want to do with the loss.
Do you just need the value so you know what the average for the dataloaders are? Or is it something else? More particularly, I don’t understand you you to backward the loss_tot.
If you look at how it works, I think loss_tot will be loss of the last batch of the last dataloader + losses of the last batches of the dataloaders. It doesn’t make sense.
Usually NN models are trained using mini-batches. That’s why I suggest to just drop the mean loss backward part. With your code, you are trying to train with BOTH mini batches (the inner loss backward) AND also dataset/dataloader wise (once every len(dataloader)) (outer total_loss backward). This is not consistent in that you have so much more mini batches than datasets/dataloaders and you end up having those dataset/dataloader updates having little significance.
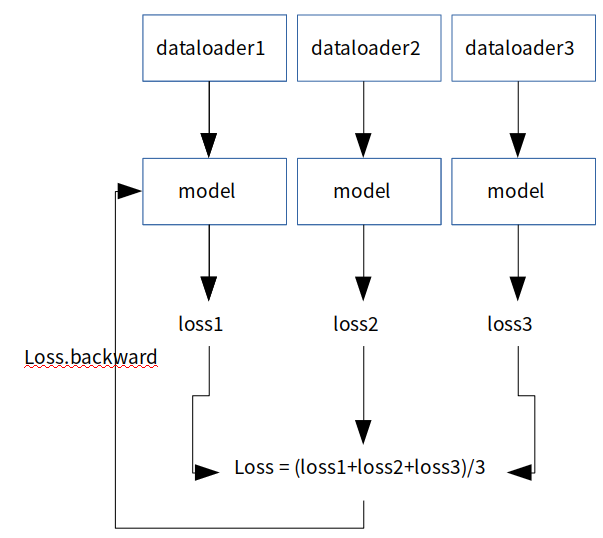
If you insist to do averaging, perhaps you can do zipping of the datasets, then in each batch, calculate the loss for each of the batch from difference datasets and then averaging the loss and backward.
I will also refer to the explanation related to zip.
I think integrating the dataloader is an efficient way. I tried, but the data loaders I made have different image sizes and batch sizes. So the integration failed.
In addition, is there a way to learn the input size and batch size differently, or is there an example that I can refer to?
For example,
multi_scale = [(1025, 512), (512, 256), (256, 128)]
multi_batch = [3, 4, 12]
After setting as follows, I would like to configure the batch size according to the input size.
I couldn’t find a way to integrate it so I configured the dataloader differently.