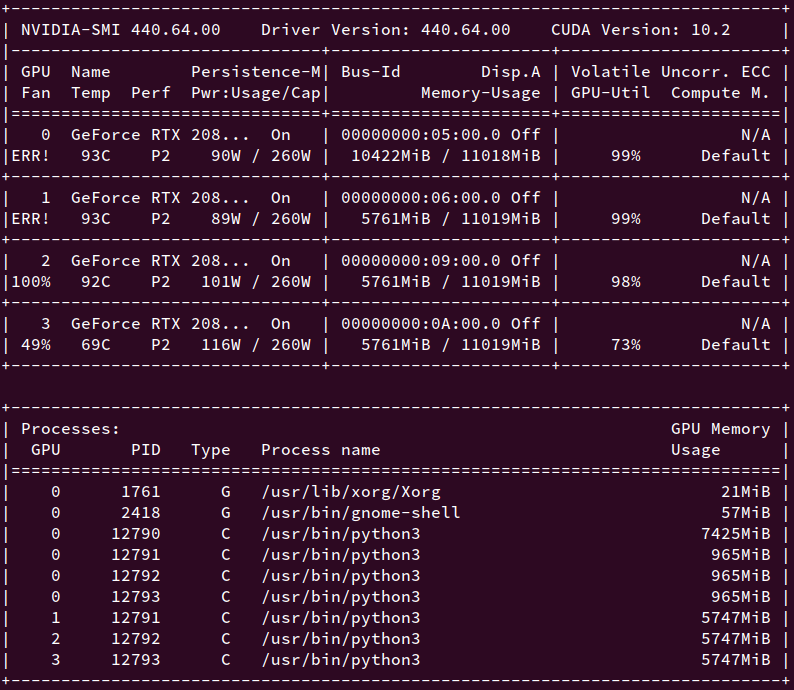
When training a model with DDP, GPU for rank 0 consumes much higher memory than others.
Because of that GPU, I cannot increase batch-size for training.
Is there a good way to deal it with?
1 Like
Hey @jaehyung.ca did you intentionally create any tensor on cuda:0 from every process? If not, it might be some lib/code accidentally create states on cuda:0. To avoid this, you can set CUDA_VISIBLE_DEVICES env var to make sure that all processes only sees one GPU.
Thank for the reply @mrshenli
I haven’t set explicitly device cuda:0 at any point.
And even in the official DDP example code shows the same unbalanced GPU memory consumption.
I solved the issue by setting torch.cuda.set_device(args.local_rank) which works the same as setting CUDA_VISIBLE_DEVICES.
2 Likes