I have a question regarding the “preferred” setup for training a more complex model in parallel.
Let’s assume I have a GAN model with an additional encoder and some additional losses (VGG, L1, L2) as shown in the illustration here:
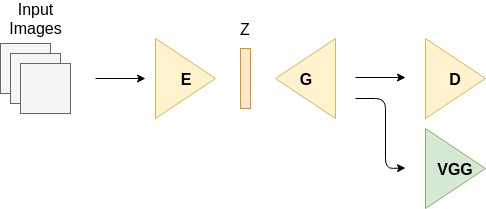
I saw two main patterns on how to use such a setup with torch.nn.DataParallel
Pattern 1:
One has been used in the pix2pixHD implementation from Nvidia.
As you see in models->pix2pixHD_model.py they wrapped all the networks and losses and even optimizers in a module. To parallize it using multiple GPUs they then call torch.nn.DataParallel on the whole model.
Pattern 2:
The other option is to call torch.nn.DataParallel on each of the networks individually as you show for example in the DCGAN tutorial. This setup is much more convenient since you don’t have to deal with issues regarding multiple inputs/outputs and separating model from logging using tensorboardX etc.
My question is now. Would you suggest to use one or the other pattern when using let’s say 8 GPUs (V100) on a single instance on AWS/ Google?
I played around with both setups and didn’t see any crucial performance advantage using one or the other. But pattern 1 is really annoying since it’s not how I would typically write nice PyTorch code.
From my understanding wrapping each network itself with torch.nn.DataParallel results in lots of scatter and gather operations since the intermediate results will be collected by the “host GPU”, correct? So the higher the [communication/ computation] ratio is the worse it gets having all those models wrapped in DataParallel individually?
Thanks a lot for your feedback and keep up the good work, PyTorch really rocks!