Hi, all,
Recently, I want to use PyTorch to build a slightly special network with the following structure:
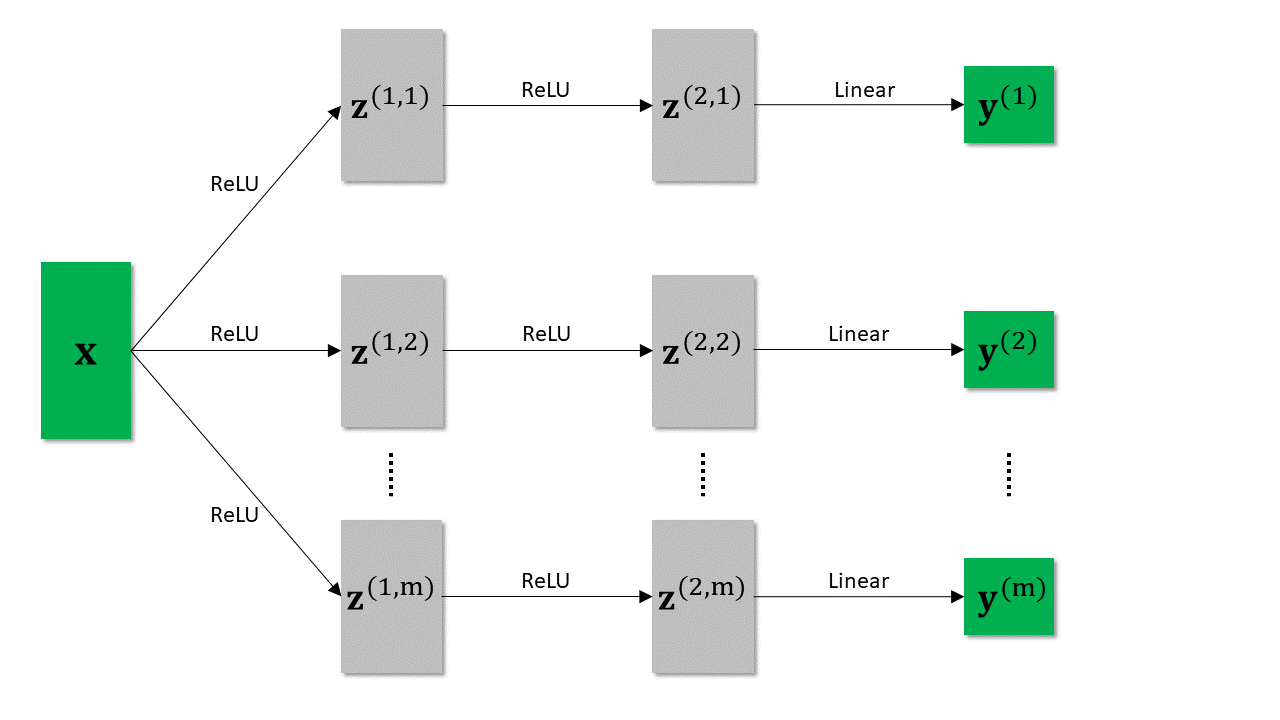
In the above network, the green boxes correspond to known variables, i.e., input vector x and m label vectors y^(1), …, y^(m). Here each y^(i) is a one-hot vector with value (1,0) or (0,1). And the remaining gray boxes indicate hidden representations (e.g., z^(1,1) and z^(2,m)).
My question is for a given positive integer m>1, how to implement such a network in nn.Module class? I guess maybe I need to use nn.ModuleList() and the for loop.
Could anyone please give a further suggestion or comment? Thanks in advance.
