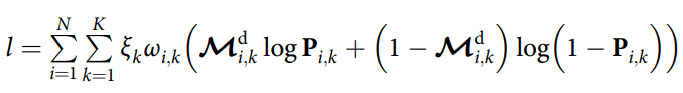I have a multiclass classification problem and there are some inter-class relationship. Then a modified version of Cross-Entropy Loss Function is used.
, where P is the probability and M is the label.
For short, in addtion to log_softmax(), I need to implement log(1 - softmax(X)), let’s call it log1m_softmax(). However, log1m_softmax() is numerically unstable even with LogSumExp trick.
I believe that I understand the implemention of numerically stable log_softmax() well, which has been well explained here.
A related disscusion can be found here, but it leads to another numerical problem of log(1 - exp(x)) when x underflowes to zero.
Please help me to find a stable log1m_softmax(), thank you!
Can you also not get away with using the original trick for log softmax, trick of subtracting max value?
In the original trick of logsoftmax, the denomitor was numerically stable while summing over all exponential values (with max value subtracted in the power)
The denominator for your case is the same, the numerator will be the same except for the one term which is absent. So, it seems that numerator is also stable ??
This is also discussed in the stats.stackexchange thread you linked to.
You can implement your numerically-stable log1m_softmax() “by hand”
along the lines discussed in that thread.
You can also use pytorch’s logsumexp() to compute log1m_softmax()
without, in effect, reimplementing the log-sum-exp trick.
With a little manipulation, you can zero out the i == j term in probability
space (i.e., in “exp” space) by replacing the term with -inf (or a very
large negative number) in log space (i.e., the space of your original X)
and then apply pytorch’s logsumexp() to both the numerator and
denominator of the above expression for 1 - softmax (X).
Consider:
>>> import torch
>>> print (torch.__version__)
1.13.0
>>>
>>> _ = torch.manual_seed (2022)
>>>
>>> X = torch.tensor ([-1000, -1000, 1000.0])
>>>
>>> X.softmax (0) # softmax underflows to zero
tensor([0., 0., 1.])
>>> X.softmax (0).log() # log gives -inf
tensor([-inf, -inf, 0.])
>>> X.log_softmax (0) # numerically-stable version uses log-sum-exp trick internally
tensor([-2000., -2000., 0.])
>>>
>>> 1 - X.softmax (0) # (1 - softmax) underflows to zero
tensor([1., 1., 0.])
>>> (1 - X.softmax (0)).log() # log gives -inf
tensor([0., 0., -inf])
>>> # use pytorch's logsumexp() to implement numerically-stable version
>>> n = X.size (0)
>>> (X.unsqueeze (0).expand (n, n) + torch.diag (-torch.ones_like (X) / 0)).logsumexp (1) - X.logsumexp (0)
tensor([ 0.0000, 0.0000, -1999.3069])
>>>
>>> Y = torch.randn (5) # check against unstable version with random data (that doesn't underflow)
>>> Y
tensor([ 0.1915, 0.3306, 0.2306, 0.8936, -0.2044])
>>> (1 - Y.softmax (0)).log()
tensor([-0.1864, -0.2175, -0.1946, -0.4203, -0.1216])
>>> n = Y.size (0)
>>> (Y.unsqueeze (0).expand (n, n) + torch.diag (-torch.ones_like (Y) / 0)).logsumexp (1) - Y.logsumexp (0)
tensor([-0.1864, -0.2175, -0.1946, -0.4203, -0.1216])
Thanks a lot for your answer code and explaination.
Adding -inf to the term j== i or making xi = - inf can remove the term perfectly in probability space (i.e., exp(-inf) = 0), and then combine this with logsumexp(), a numerically stable log1m_softmax() can be achived. This is the solution to this question!
However, I cannot find the solution in the stackexchange thread in all answers, which don’t introduce this -inf trick and lead to other unstable problem. Could you please point out the one where you found the answer?
I didn’t mean to suggest that the stackexchange thread proposes using -inf to “zero out” the extra term in log-probability space. I chose to go
this route in order to use pytorch’s logsumexp() and avoid implementing
a version of the log-sum-exp trick that works for the terms that show up
in the expression for log (1 - softmax (X)).
I tried for days to develop an efficient way of computing a stable log(1-softmax) but with no success.
I searched in many forums but it seems your solution is the only one that is really stable : your method outputs log(1-softmax(x)) = [0., 0., -1001.3068] when x = [-1000., -1000., 0], which is very accurate (validated using the mpmath package), while all other solutions still output log(1-softmax(x)) = [0., 0., -inf]. In addition, the backward function does not produce any nan values which is nice.
The problem with your approach is that memory and compute requirements scale quadratically with the size of x.
Do you see any possible improvements to make its complexity linear?
I do not believe that the method I posted above outputs this specific result.
(See the example script, below.) I think you must have a mistake in this
test case you posted.
The singularity / numerical instability in log (1-softmax (X)) occurs
only when largest element of X is sufficiently larger than the others so
that softmax (X) contains an element equal (or very nearly equal) to
one. Then the corresponding element of 1-softmax (X) approaches
zero and the log() diverges.
In the approach I posted above, it was convenient to “zero out” all of the
terms in X – whether or not they were potentially problematic – at the
quadratic cost of expand()ing X into a square matrix with -inf along its
diagonal.
It is indeed possible to deal only with largest term in X – the only one
which could be problematic – in linear time and space, but at the cost
of additional code complexity and, roughly speaking, implementing the
log-sum-exp trick “by hand.”
This is illustrated in the following script that implements a linear algorithm
and compares its results with the quadratic algorithm I posted above:
import torch
print (torch.__version__)
_ = torch.manual_seed (2024)
# algorithm linear in length of X
def log1msm (X): # for one-dimensional tensor X
xm, im = X.max (0) # largest value in X is the potential problem
X_bar = X - xm # uniform shift doesn't affect softmax (except numerically)
lse = X_bar.logsumexp (0) # denominator for final result
sumexp = X_bar.exp().sum() - X_bar.exp() # sumexp[im] potentially zero
sumexp[im] = 1.0 # protect against log (0)
log1msm = sumexp.log() # good for all but i = im
X_bar = X_bar.clone() # to support backward pass
X_bar[im] = -float ('inf') # "zero out" xm in log space
log1msm[im] = X_bar.logsumexp (0) # replace bad xm term
log1msm -= lse # final result
return log1msm
def log1msmB (X): # previous algorithm quadratic in length of X
n = X.size (0)
return (X.unsqueeze (0).expand (n, n) + torch.diag (-torch.ones_like (X) / 0)).logsumexp (1) - X.logsumexp (0)
y = torch.randn (8)
y[1] = -1000.0
y.requires_grad = True
z = torch.randn (8)
z[1] = 1000.0
z.requires_grad = True
xl = [ # list of test tensors for log1msm()
torch.tensor ([-1000.0, -1000.0, 0.0], requires_grad = True),
torch.tensor ([-1000.0, -1000.0, 1000.0], requires_grad = True),
torch.tensor ([-1000.0, 1000.0, 1000.0], requires_grad = True),
torch.randn (8, requires_grad = True),
y,
z
]
for X in xl: # compare log1msm() with previous quadratic version
print ('X = ...')
print (X)
lg1m = log1msm (X)
lg1m.sum().backward()
X_grad = X.grad
X.grad = None
lg1mB = log1msmB (X)
lg1mB.sum().backward()
X_grad_B = X.grad
print ('log1msm (X) = ...')
print (lg1m)
print ('log1msmB (X) = ...')
print (lg1mB)
print ('torch.allclose (lg1m, lg1mB, atol = 1.e-4):', torch.allclose (lg1m, lg1mB, atol = 1.e-4))
print ('X_grad = ...')
print (X_grad)
print ('X_grad_B = ...')
print (X_grad_B)
print ('torch.allclose (X_grad, X_grad_B, atol = 1.e-4):', torch.allclose (X_grad, X_grad_B, atol = 1.e-4))
Yes! I made a little mistake. This result appears when x = [-1000., -1000., 2].
Stability and precision study
To confirm the stability and precision of your function (let’s call it KF), I compared its output and its gradient with the “real” values of the log(1-softmax).
The “real” values of log(1-softmax) are computed using the mpmath package using a ridiculously high precision (2000 bits).
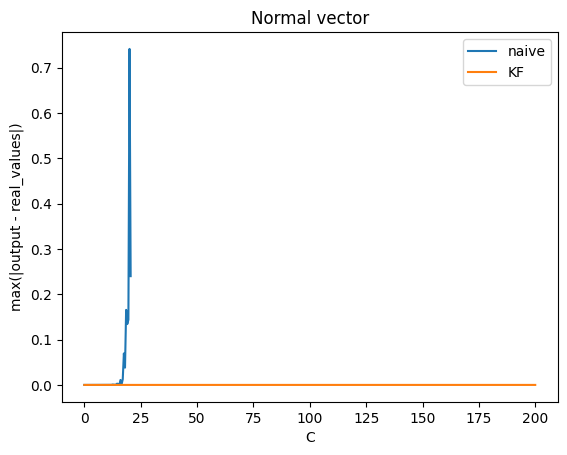
The input I used is a randomly generated vector X of 100 elements on a normal distribution N(0,1) with a little modification : I set an element of X to be equal to C and C varies from 0 to 100. As C grows, the sum of the exponents of X will be almost equal to exp(C) which creates the numerical instability.
The next image is a plot of the maximum absolute error between KF’s output and the “real” output of log(1-softmax), noted max(abs(KF(X) - real_values)), with respect to C. I also plotted the naive implementation torch.log(1-torch.softmax(X)) for reference. As we can see, KF stays stable and accurate while the “naive” approach diverges to infinity after C ≈ 25. The maximum absolute error of KF, reported in this test, is 6.56e-6.
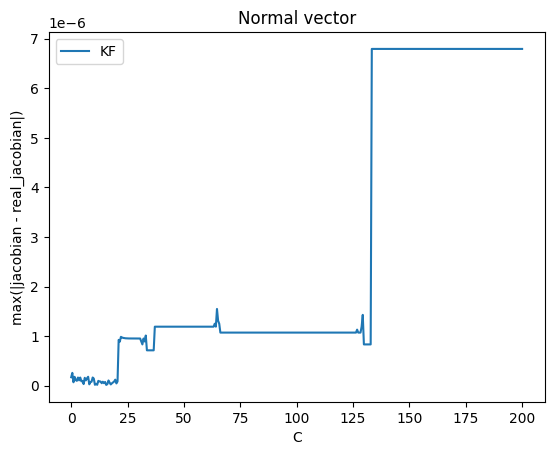
To test the gradient, the next image is a plot of max(abs(J(KF(X)) - real_jacobian)) with respect to C, where J(KF(X)) is the Jacobian matrix of KF with respect to X. We can see that the absolute error stays small even for large values of C. The maximum absolute error reported in this test is 6.79e-6.
Generalization to multi-dimensional tensors
I also generalized your function to support the “dim” argument present in torch.log_softmax to be able to use it with multi-dimensional tensors:
def log1m_softmax(X : torch.Tensor, dim : int):
xm, im = X.max(dim, keepdim=True) # largest value in X is the potential problem
X_bar = X - xm # uniform shift doesn't affect softmax (except numerically)
lse = X_bar.logsumexp(dim, keepdim=True) # denominator for final result
sumexp = X_bar.exp().sum(dim, keepdim=True) - X_bar.exp() # sumexp[im] potentially zero
sumexp.scatter_(dim, im, 1.0) # protect against log (0)
log1msm = sumexp.log() # good for all but i = im
X_bar = X_bar.clone() # to support backward pass
X_bar.scatter_(dim, im, -float ('inf')) # "zero out" xm in log space
log1msm.scatter_(dim, im, X_bar.logsumexp (dim).view(im.shape)) # replace bad xm term
log1msm -= lse # final result
return log1msm