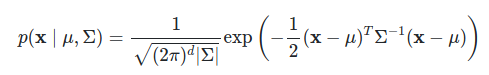The problem is in np.linalg.solve(). I know that with .solve it is possible to solve a linear matrix equation or a system of linear scalar equations. So I want to know if there is a pytorch function that does exactly the same? Help is much appriciated
Thanks a lot, I will try that. But do you know if there is a function in pytorch which does the same like np.linalg.solve in the above formula? Thank you very much!
@InnovArul I have got still one question. Is the part for the Mahalanobis-distance in the formula you wrote: dist = multivariate_normal.MultivariateNormal(loc=torch.zeros(5), covariance_matrix=torch.eye(5))
the same as
because in literature the Mahalanobis-distance is given with square root instead of -0.5 as a factor
@KFrank I should have read your last post a little closer because you wrote “Cholesky- factorization route” and added both functions. Thank you for the helpful code snippet
So in my case I just have to write:
tmp = torch.cholesky(covariance)
res = torch.cholesky_solve(x_m, tmp)
Does it matter if cholesky_solve() takes first the vector and then the matrix or the other way round? And what if x_m is a distance matrix where the entries are eucledian distances? I know that Mahalanobis-distances are there to calculate the distances between a data point and a distribution
but is it desired that we first calculate a Euclidean distance with x_m and then subsequently calculate the Mahalanobis distance?
Hey guys, thanks for the replies. In my case I have a single covariance matrix of a neighborhood (kernel) of a given pixel of an image and I need to compute the log_prob for all the pixels in the image using the neighborhood for them. i.e. for each pixel i,j I have to use a fixed and previously computed covariance matrix and mean to compute the multivariate normal log_prob that uses the neighbor pixels [i±k,j±k] being k the kernel size. One approach is to use torch.tensor.unfold to generate a view of the image tensor with the windows matching the kernel size, reshape and pass it to log_prob from the Multivariate normal. This approach works but it uses a lot of memory. Would anyone know a faster/better way to do that?