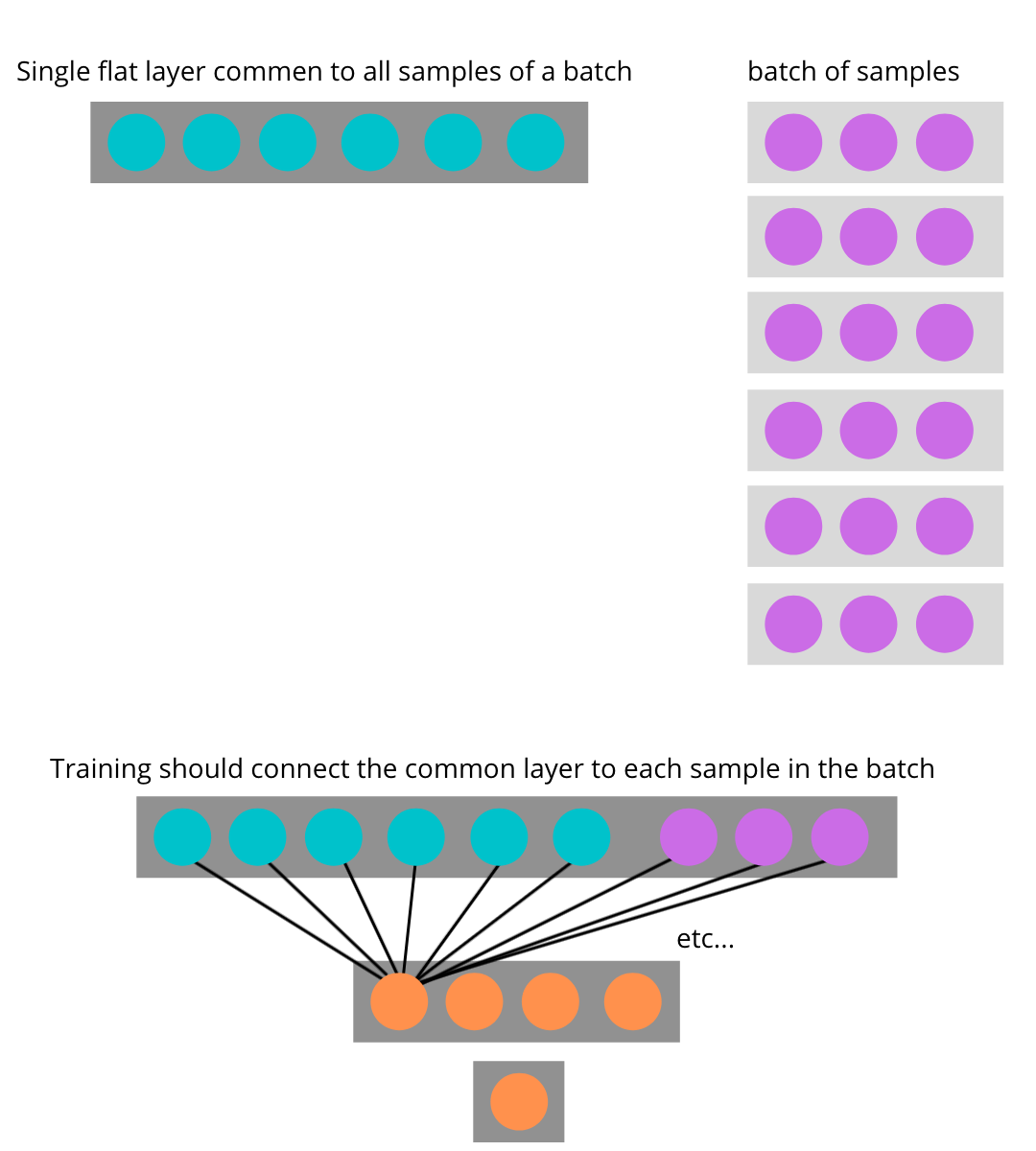
I spent some time going over the variations in the thread and I don’t quite see the situation I’m referring to. Perhaps I’ve missed it.
To simplify my issue I’m including code with error and my “work around”.
Here is the code which breaks because the torch.cat() bumps on not having the proper dimensions…
layers = [ torch.nn.Linear( 15, 5),
torch.nn.ReLU( inplace=True),
torch.nn.Linear( 5, 3),
torch.nn.ReLU( inplace=True),
torch.nn.Linear( 3, 1),
torch.nn.Sigmoid() ]
model = torch.nn.Sequential( *layers)
single_layer = torch.randn( (1,10))
batch = torch.randn( (100,5))
input_layer = torch.cat( (single_layer, batch), dim=1)
output = model( input_layer)
And here is what I’ve done to get around the issue…
layers = [ torch.nn.Linear( 15, 5),
torch.nn.ReLU( inplace=True),
torch.nn.Linear( 5, 3),
torch.nn.ReLU( inplace=True),
torch.nn.Linear( 3, 1),
torch.nn.Sigmoid() ]
model = torch.nn.Sequential( *layers)
single_layer = torch.randn( (1,10))
print( f'Constant Layer Size:: { single_layer.size()}')
batch = torch.randn( (100,5))
print( f'Batch Size:: { batch.size()}')
replicated_single_layer = torch.ones( (batch.size(0), single_layer.size(1)))
replicated_single_layer *= single_layer
print( f'Replicated Layer Size: { replicated_single_layer.size()}')
input_layer = torch.cat( (replicated_single_layer, batch), dim=1)
print( f'Input Layer Size: { input_layer.size()}')
output = model( input_layer)
print( output.size())
Perhaps the thread you’ve suggested has the solution staring me in the face and I’m just lost on the variation of its implementation.