Hi,
I’m trying to analyze the reliability of a quantized model
But I have a question:
How can I change the respondent value to the model
I change the value directly like what I do in normal models that will not affect the value of the model’s value
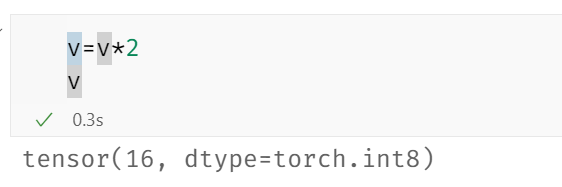
like:
number.int_repr()[0]=number.int_repr()[0]*2
number.int_repr()[0]
# Don't have any change
number.dequantize()=number.dequantize()*2
number.dequantize()
# Don't change too
what kind of changes you want? if you want multiplications by constant then you can just to quantized_tensor = quantized_tensor * 2 I think. we also have a list of tensor methods defined here: Quantization API Reference — PyTorch master documentation
My fault,
Thank you for your patience
I have read this API Reference, but it can’t help my work
I want to change a number at specified position of matrix
First I get a value from the original matrix
Then I change this value
I tried to assign this value to the respondent number
But, it doesn’t affect this matrix at all.
Thank you,
I successfully changed weight in quant models.
But when I use _make_per_tensor_quantized_tensor, it’s changeable.
However, when I use _make_per_channel_quantized_tensor, it’s not changeable
You pretty much can’t do quantized inference with cuda, there are no native quantized cuda kernels atm, our team is working to support lowering to custom backends using Fx to TRT but its not complete yet.
also maybe @jerryzh168 can confirm, but I believe the intended solution was to do:
goal: set int_repr of a quantized tensor x to 3.
# x is per channel quantized tensor
x_int = x.int_repr()
x_int[0][0][0][0]=3
x_new = torch._make_per_tensor_quantized_tensor(x_int, x.per_channel_scales(), ... )