Context: the input is a 520x520 image of a cell slide, and the output is a heatmap of where the macrophage cell centres are:
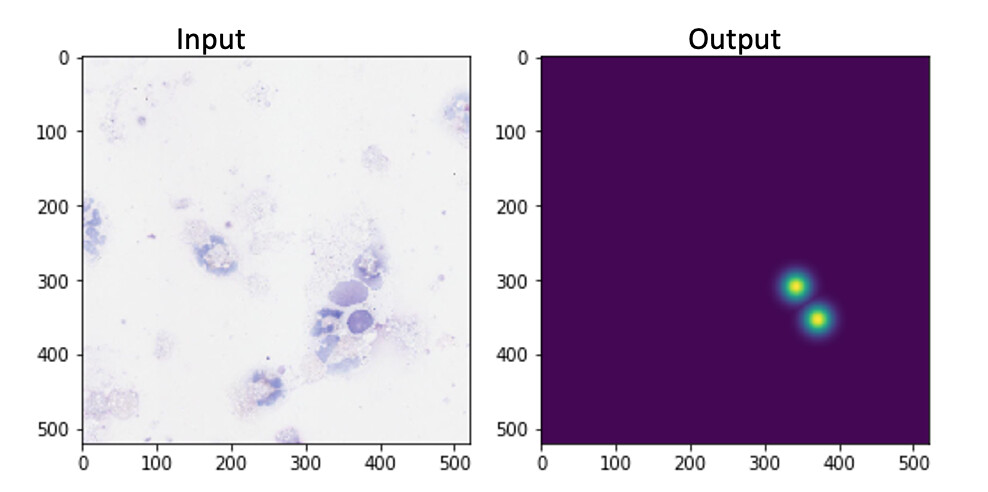
This means the input shape is 3x520x520, and the output shape should be 1x520x520.
Problem: I’m trying to use transfer learning with a pretrained semantic segmentation model to get the output from the input. I’m using deeplabv3_resnet50 from torchvision.models.segmentation. However, when I print the model summary with torchinfo.summary(), the input shape is correct (1x3x520x520), but the output shape is something unexpected (either 1x21x520x520 or 1x21x65x65?!)
==============================================================================================================
Layer (type (var_name)) Input Shape Output Shape Trainable
==============================================================================================================
DeepLabV3 (DeepLabV3) [1, 3, 520, 520] [1, 21, 520, 520] True
├─IntermediateLayerGetter (backbone) [1, 3, 520, 520] [1, 2048, 65, 65] True
│ └─Conv2d (conv1) [1, 3, 520, 520] [1, 64, 260, 260] True
│ └─BatchNorm2d (bn1) [1, 64, 260, 260] [1, 64, 260, 260] True
│ └─ReLU (relu) [1, 64, 260, 260] [1, 64, 260, 260] --
│ └─MaxPool2d (maxpool) [1, 64, 260, 260] [1, 64, 130, 130] --
│ └─Sequential (layer1) [1, 64, 130, 130] [1, 256, 130, 130] True
│ │ └─Bottleneck (0) [1, 64, 130, 130] [1, 256, 130, 130] True
│ │ └─Bottleneck (1) [1, 256, 130, 130] [1, 256, 130, 130] True
│ │ └─Bottleneck (2) [1, 256, 130, 130] [1, 256, 130, 130] True
│ └─Sequential (layer2) [1, 256, 130, 130] [1, 512, 65, 65] True
│ │ └─Bottleneck (0) [1, 256, 130, 130] [1, 512, 65, 65] True
│ │ └─Bottleneck (1) [1, 512, 65, 65] [1, 512, 65, 65] True
│ │ └─Bottleneck (2) [1, 512, 65, 65] [1, 512, 65, 65] True
│ │ └─Bottleneck (3) [1, 512, 65, 65] [1, 512, 65, 65] True
│ └─Sequential (layer3) [1, 512, 65, 65] [1, 1024, 65, 65] True
│ │ └─Bottleneck (0) [1, 512, 65, 65] [1, 1024, 65, 65] True
│ │ └─Bottleneck (1) [1, 1024, 65, 65] [1, 1024, 65, 65] True
│ │ └─Bottleneck (2) [1, 1024, 65, 65] [1, 1024, 65, 65] True
│ │ └─Bottleneck (3) [1, 1024, 65, 65] [1, 1024, 65, 65] True
│ │ └─Bottleneck (4) [1, 1024, 65, 65] [1, 1024, 65, 65] True
│ │ └─Bottleneck (5) [1, 1024, 65, 65] [1, 1024, 65, 65] True
│ └─Sequential (layer4) [1, 1024, 65, 65] [1, 2048, 65, 65] True
│ │ └─Bottleneck (0) [1, 1024, 65, 65] [1, 2048, 65, 65] True
│ │ └─Bottleneck (1) [1, 2048, 65, 65] [1, 2048, 65, 65] True
│ │ └─Bottleneck (2) [1, 2048, 65, 65] [1, 2048, 65, 65] True
├─DeepLabHead (classifier) [1, 2048, 65, 65] [1, 21, 65, 65] True
│ └─ASPP (0) [1, 2048, 65, 65] [1, 256, 65, 65] True
│ │ └─ModuleList (convs) -- -- True
│ │ └─Sequential (project) [1, 1280, 65, 65] [1, 256, 65, 65] True
│ └─Conv2d (1) [1, 256, 65, 65] [1, 256, 65, 65] True
│ └─BatchNorm2d (2) [1, 256, 65, 65] [1, 256, 65, 65] True
│ └─ReLU (3) [1, 256, 65, 65] [1, 256, 65, 65] --
│ └─Conv2d (4) [1, 256, 65, 65] [1, 21, 65, 65] True
├─FCNHead (aux_classifier) [1, 1024, 65, 65] [1, 21, 65, 65] True
│ └─Conv2d (0) [1, 1024, 65, 65] [1, 256, 65, 65] True
│ └─BatchNorm2d (1) [1, 256, 65, 65] [1, 256, 65, 65] True
│ └─ReLU (2) [1, 256, 65, 65] [1, 256, 65, 65] --
│ └─Dropout (3) [1, 256, 65, 65] [1, 256, 65, 65] --
│ └─Conv2d (4) [1, 256, 65, 65] [1, 21, 65, 65] True
==============================================================================================================
Total params: 42,004,074
Trainable params: 42,004,074
Non-trainable params: 0
Total mult-adds (G): 178.72
==============================================================================================================
Input size (MB): 3.24
Forward/backward pass size (MB): 2294.42
Params size (MB): 168.02
Estimated Total Size (MB): 2465.68
==============================================================================================================
Does anyone know why the output shape is turning out like that and how to fix it so that it’s 1x1x520x520?