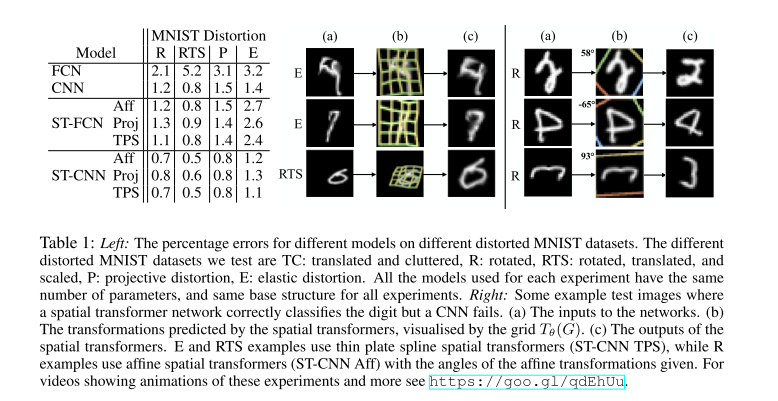
```python
from torch.autograd import Variable
N_PARAMS = {'affine': 6,
'translation':2,
'rotation':1,
'scale':2,
'shear':2,
'rotation_scale':3,
'translation_scale':4,
'rotation_translation':3,
'rotation_translation_scale':5}
# Spatial transformer network forward function
def stn(x, theta, mode='affine'):
if mode == 'affine':
theta1 = theta.view(-1, 2, 3)
else:
theta1 = Variable( torch.zeros([x.size(0), 2, 3], dtype=torch.float32, device=x.get_device()), requires_grad=True)
theta1 = theta1 + 0
theta1[:,0,0] = 1.0
theta1[:,1,1] = 1.0
if mode == 'translation':
theta1[:,0,2] = theta[:,0]
theta1[:,1,2] = theta[:,1]
elif mode == 'rotation':
angle = theta[:,0]
theta1[:,0,0] = torch.cos(angle)
theta1[:,0,1] = -torch.sin(angle)
theta1[:,1,0] = torch.sin(angle)
theta1[:,1,1] = torch.cos(angle)
elif mode == 'scale':
theta1[:,0,0] = theta[:,0]
theta1[:,1,1] = theta[:,1]
elif mode == 'shear':
theta1[:,0,1] = theta[:,0]
theta1[:,1,0] = theta[:,1]
elif mode == 'rotation_scale':
angle = theta[:,0]
theta1[:,0,0] = torch.cos(angle) * theta[:,1]
theta1[:,0,1] = -torch.sin(angle)
theta1[:,1,0] = torch.sin(angle)
theta1[:,1,1] = torch.cos(angle) * theta[:,2]
elif mode == 'translation_scale':
theta1[:,0,2] = theta[:,0]
theta1[:,1,2] = theta[:,1]
theta1[:,0,0] = theta[:,2]
theta1[:,1,1] = theta[:,3]
elif mode == 'rotation_translation':
angle = theta[:,0]
theta1[:,0,0] = torch.cos(angle)
theta1[:,0,1] = -torch.sin(angle)
theta1[:,1,0] = torch.sin(angle)
theta1[:,1,1] = torch.cos(angle)
theta1[:,0,2] = theta[:,1]
theta1[:,1,2] = theta[:,2]
elif mode == 'rotation_translation_scale':
angle = theta[:,0]
theta1[:,0,0] = torch.cos(angle) * theta[:,3]
theta1[:,0,1] = -torch.sin(angle)
theta1[:,1,0] = torch.sin(angle)
theta1[:,1,1] = torch.cos(angle) * theta[:,4]
theta1[:,0,2] = theta[:,1]
theta1[:,1,2] = theta[:,2]
grid = F.affine_grid(theta1, x.size())
x = F.grid_sample(x, grid)
return x
class Net(nn.Module):
def __init__(self, stn_mode='affine'):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
self.stn_mode = stn_mode
self.stn_n_params = N_PARAMS[stn_mode]
# Spatial transformer localization-network
self.localization = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=7),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True),
nn.Conv2d(8, 10, kernel_size=5),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True)
)
# Regressor for the 3 * 2 affine matrix
self.fc_loc = nn.Sequential(
nn.Linear(10 * 3 * 3, 32),
nn.ReLU(True),
nn.Linear(32, self.stn_n_params)
)
# Initialize the weights/bias with identity transformation
self.fc_loc[2].weight.data.fill_(0)
self.fc_loc[2].weight.data.zero_()
if self.stn_mode == 'affine':
self.fc_loc[2].bias.data.copy_(torch.tensor([1, 0, 0, 0, 1, 0], dtype=torch.float))
elif self.stn_mode in ['translation','shear']:
self.fc_loc[2].bias.data.copy_(torch.tensor([0,0], dtype=torch.float))
elif self.stn_mode == 'scale':
self.fc_loc[2].bias.data.copy_(torch.tensor([1,1], dtype=torch.float))
elif self.stn_mode == 'rotation':
self.fc_loc[2].bias.data.copy_(torch.tensor([0], dtype=torch.float))
elif self.stn_mode == 'rotation_scale':
self.fc_loc[2].bias.data.copy_(torch.tensor([0,1,1], dtype=torch.float))
elif self.stn_mode == 'translation_scale':
self.fc_loc[2].bias.data.copy_(torch.tensor([0,0,1,1], dtype=torch.float))
elif self.stn_mode == 'rotation_translation':
self.fc_loc[2].bias.data.copy_(torch.tensor([0,0,0], dtype=torch.float))
elif self.stn_mode == 'rotation_translation_scale':
self.fc_loc[2].bias.data.copy_(torch.tensor([0,0,0,1,1], dtype=torch.float))
def stn(self, x):
x = stn( x, self.theta(x), mode=self.stn_mode)
return x
def theta(self, x):
xs = self.localization(x)
xs = xs.view(-1, 10 * 3 * 3)
theta = self.fc_loc(xs)
return theta
def forward(self, x):
# transform the input
x = self.stn(x)
# Perform the usual forward pass
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x)