Thanks for this really useful script! I tried it on my neural network (an implementation of the Probabilistic U-Net) and I got an assertion error:
AssertionError: <ReluBackward1 object at 0x7fb5c68b7e10>
I tried to have the code bypass the assertion with a try-except block (‘pass’ in the except case), the code goes forward and I get a graph representation. However, I feel the assertion error hints at something deeper but I’m not clear on how to interpret it. Does it mean that no gradients flow via this operation even though its present on the forward path?
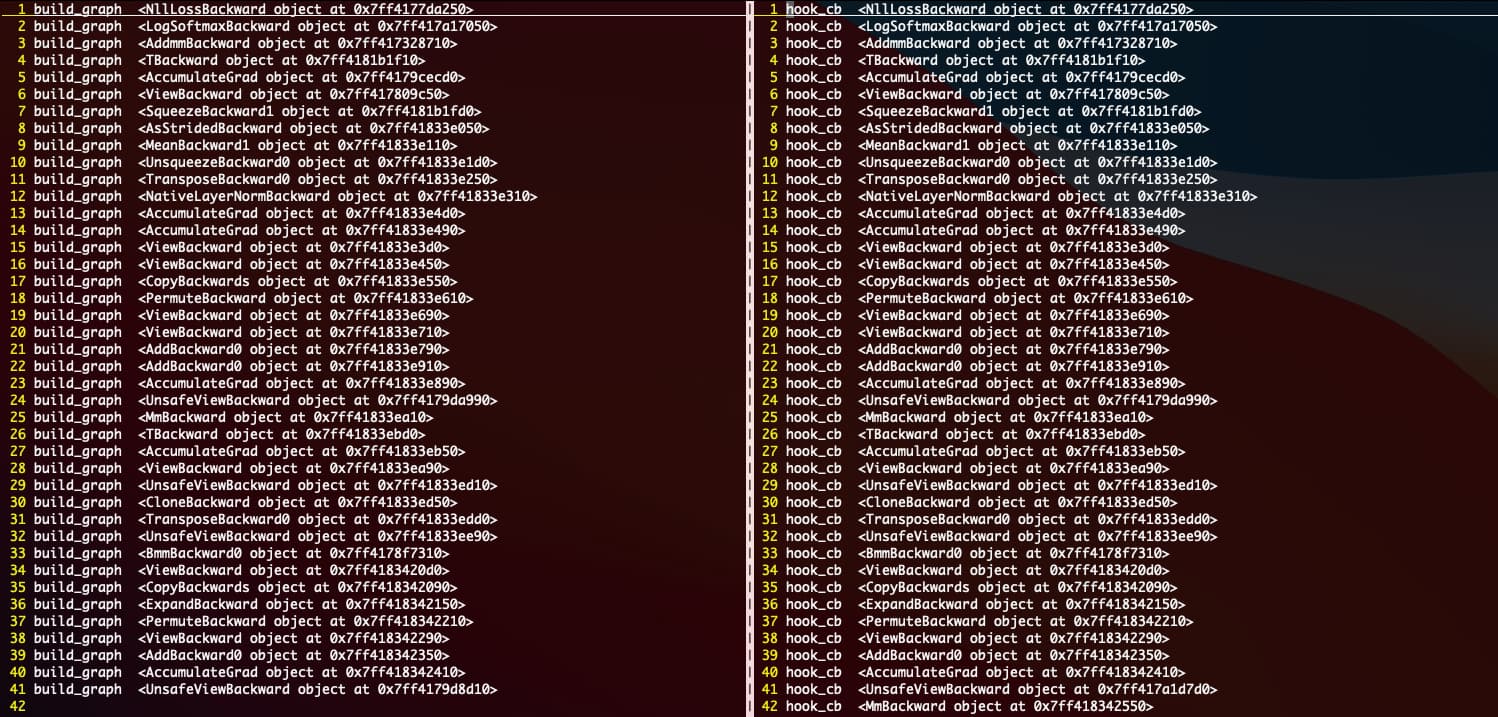
Hi @tom, I noticed between calling iter_graph(var.grad_fn, hook_cb) and iter_graph(var.grad_fn, build_graph), the function addresses can change.
You can see the attached screenshot for an example. The left side is a printout of the visited functions from iter_graph(var.grad_fn, build_graph), and the right side is that of iter_graph(var.grad_fn, hook_cb). The right side finished first and populated the fn_dict. However, when building graph, the same function is now at a different address, triggering the assertion in build_graph(). Is there any way to fix this? Thanks.
I’m not sure what would cause this, except maybe that the Python object is de-allocated and a new one created from the C++ one when requested. Maybe @albanD knows more…
I think the tensorboard can be used for gradient visualization
writer = torch.utils.tensorboard.SummaryWriter("runs/")
for name, param in model.named_parameters():
writer.add_histogram(name + '/grad', param.grad, global_step=epoch)
Any consistently small or large gradients indicate a vanishing or exploding gradient problem, respectively.
Also, ideally, the gradients should be centered around zero and have a relatively narrow distribution. If the distribution is wide, this could indicate instability in the model