I am using the FlyingThings3D and Monkaa datasets.
During training, I load the images and disparity data. The image tensor is of shape: [2, 3, 256, 256], and disparity/depth tensor is of shape: [2, 1, 256, 256] (batch size, channels, height, width). I would like to use Conv3D, so I need to combine these two tensors and create a new tensor of shape: [2, 3, 256, 256, 256] (batch size, channels, depth, height, width).
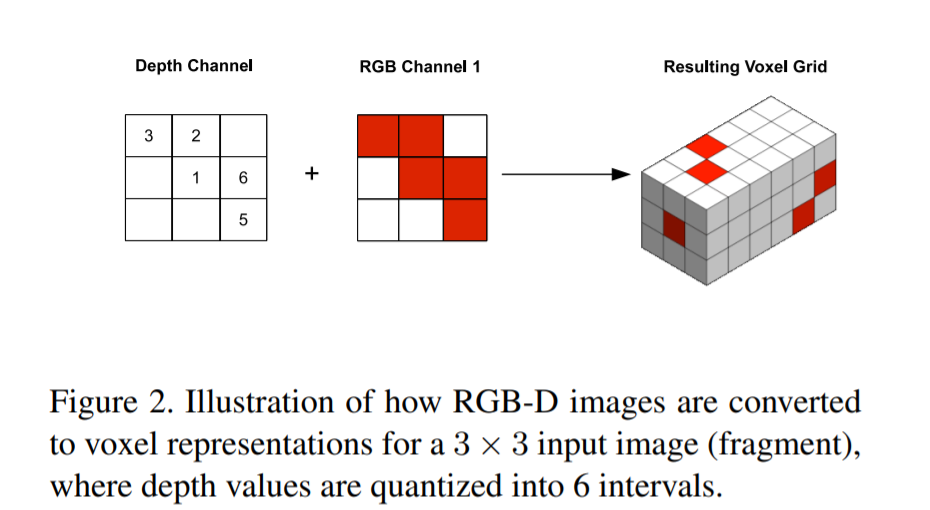
The depth values range from 0-400, and a possibility is to divide that into intervals, e.g., 4 intervals of 100. I would like the resulting tensor to look like a voxel, similarly to the technique used in this paper.
The training loop that iterates over the data is below:
for batch_id, sample in enumerate(train_loader):
sample = {name: tensor.cuda() for name, tensor in sample.items()}
# image tensor [2, 3, 256, 256]
rgb_image = transforms.Lambda(lambda x: x.mul(255))(sample["frame"])
# translate disparity to depth
depth_from_disparity_frame = 132.28 / sample["disparity_frame"]
# depth tensor [2, 1, 256, 256]
depth_image = depth_from_disparity_frame.unsqueeze(1)
The depth values are quantized and then are used to convert the RGB images to RGB-D voxel representations. Currently, the depth tensor contains a single depth value per pixel. The values range from 0 to 400, so they can be quantized in 4 intervals. Do you have any idea or advice on how I can utilize the depth tensor to produce this kind of input representation? Thanks again.
I think the best way to do this is by forming a [2, 4, 256, 256] tensor.
As you showed in your picture, the depth (D) represents the distance.
So for each pixel in the 256x256 image, you have one R, one G, one B and now one D additional value.
But the batch (B) and the height (H) and width (W) stay the same.
So for this example you gave, I think this would be enough.
However, if what you actually want are all of the Voxels (having zero wherever the actual pixel is not present), then what you should do is change the depth D into a one hot vector encoding of the dimension you want.
So for example you mention that the range is 0-400
Then you could have a tensor [2, 3, 400, 256, 256], where 400 is the one hot vector encoding for the depth, having only a 1 in the depth where the pixel is.
I think both approaches should work, but it is up to you how you implement it.
I am sure there is a better solution instead of the for loops, but this should work
d = torch.randint(0, 400, (2, 1, 256, 256)) # Your depth tensor
x = torch.randint(0, 256, (2, 3, 256, 256)) # Your image tensor
# Your desired dimension depth
depth = 256
z = torch.zeros((2, 3, depth, 256, 256)) # Tensor with zeros
# Scaling from 400 to the desired depth
d = d * depth / 400
for b in range(2):
for h in range(256):
for w in range(256):
# Select only the desired depth for each pixel in each batch and put the actual values only there
z[b, :, int(d[b, 0, h, w]), h, w] = x[b, :, h, w]
# The tensor consists of mainly zeros, only where the depth indicates are actual RGB values
print(z)