I’m new to Pytorch. I have a pre-trained model W1 and two data point (x1, y1), (x2, y2). Firstly, I fine-tune W1 with (x1, y1) in one epoch, thus the model update ![]() can be obtained by doing
can be obtained by doing
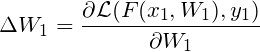
And then, I get the test loss for (x2, y2) w.r.t fine-tuned model ![]() by
by
![]()
What I want to do is to use the test_loss to update x1 by doing
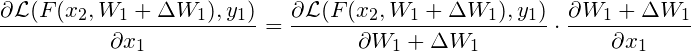
Here I offer a toy code where the model is F(x)=wx, and the two data points are (1, 1) and (2, 2) respectively.
import torch, torch.nn as nn
from torch.autograd import grad
torch.manual_seed(1)
torch.cuda.manual_seed(1)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc_blocks = nn.Sequential(
nn.Linear(1, 1, bias=False)
)
def forward(self, x):
output = self.fc_blocks(x)
return output
def weight_init(m):
if isinstance(m, nn.Linear):
nn.init.constant_(m.weight, 2.0)
net = Net()
net.apply(weight_init)
criterion = nn.MSELoss()
x_1 = torch.tensor([[1.0]], requires_grad=True)
y_1 = torch.tensor([[1.0]])
x_2 = torch.tensor([[2.0]])
y_2 = torch.tensor([[2.0]])
x_optimizer = torch.optim.SGD([x_1,], lr = 1)
net_optimizer = torch.optim.SGD(net.parameters(), lr = 1)
for i in range(1):
def closure():
net_optimizer.zero_grad()
y_pred = net(x_1)
pred_loss = criterion(y_pred, y_1)
dp_dw = grad(pred_loss, net.parameters(), create_graph=True, retain_graph=True)
dp_dw[0].backward()
print(x_1.grad)
for param in net.parameters():
param.data = param.data - param.grad.data
y_test = net(x_2)
test_loss = criterion(y_test, y_2)
test_loss.backward(create_graph=True)
print(x_1.grad)
return test_loss
x_optimizer.step(closure)
And the result is
$ python test.py
tensor([[6.]], grad_fn=<CloneBackward>)
tensor([[6.]], grad_fn=<CloneBackward>)
It seems that the x1.grad doesn’t change in step2 mainly caused by the the computation graph forgetting this operation ![]() . But I have manually re-assign the model’s parameters intead of using in-place operation implemented in
. But I have manually re-assign the model’s parameters intead of using in-place operation implemented in step() function.
What am I doing wrong here? Any help is appreciated. Thank you.

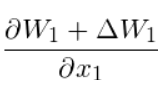 (Is it correct since \Delta W1 is a function of x1 while W1 is not a function of x? ) And it’s easy to get the gradient
(Is it correct since \Delta W1 is a function of x1 while W1 is not a function of x? ) And it’s easy to get the gradient 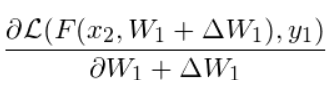 with
with