Here are some functions that can help you.
import torch
def gradient(y, x, grad_outputs=None):
"""Compute dy/dx @ grad_outputs"""
if grad_outputs is None:
grad_outputs = torch.ones_like(y)
grad = torch.autograd.grad(y, [x], grad_outputs = grad_outputs, create_graph=True)[0]
return grad
def jacobian(y, x):
"""Compute dy/dx = dy/dx @ grad_outputs;
for grad_outputs in [1, 0, ..., 0], [0, 1, 0, ..., 0], ...., [0, ..., 0, 1]"""
jac = torch.zeros(y.shape[0], x.shape[0])
for i in range(y.shape[0]):
grad_outputs = torch.zeros_like(y)
grad_outputs[i] = 1
jac[i] = gradient(y, x, grad_outputs = grad_outputs)
return jac
def divergence(y, x):
div = 0.
for i in range(y.shape[-1]):
div += torch.autograd.grad(y[..., i], x, torch.ones_like(y[..., i]), create_graph=True)[0][..., i:i+1]
return div
def laplace(y, x):
grad = gradient(y, x)
return divergence(grad, x)
Illustration
x = torch.tensor([1., 2., 3.], requires_grad=True)
w = torch.tensor([[1., 2., 3.], [0., 1., -1.]])
b = torch.tensor([1., 2.])
y = torch.matmul(x, w.t()) + b # y = x @ wT + b => y1 = x1 + 2*x2 + 3*x3 + 1 = 15, y2 = x2 - x3 + 2 = 1
dydx = gradient(y, x) # => jacobian(y, x) @ [1, 1]
jac = jacobian(y, x)
div = divergence(y, x)
```
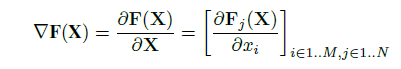
 .
.