It doesn’t seem to work for me. I was trying to benchmark the old dataset with the new IterableDataset.
Can you look out what’s wrong here?
My Cifar100 images are in folders.
def read_files(files):
images = [torch.tensor(np.array(Image.open(i))) for i in files]
yield images
class Cifar100Dataset(IterableDataset):
def __init__(self, path, folder, start, end):
self.files = [file for directory in (path / folder).ls() for file in directory.ls()]
self.start = start
self.end = end
def __iter__(self):
worker_info = torch.utils.data.get_worker_info()
if worker_info is None:
return read_files(self.files[self.start:self.end])
else:
per_worker = int(math.ceil((self.end - self.start) / float(worker_info.num_workers)))
worker_id = worker_info.id
iter_start = self.start + worker_id * per_worker
iter_end = min(iter_start + per_worker, self.end)
return iter(read_files(self.files[iter_start:iter_end]))
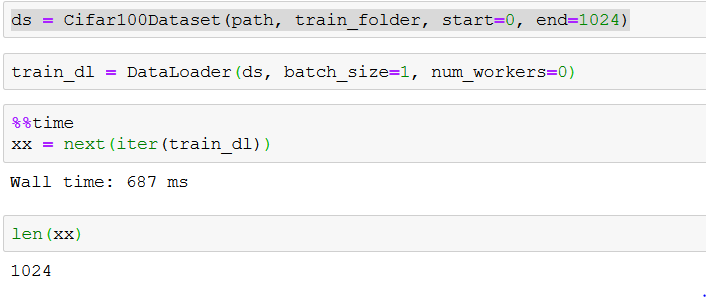
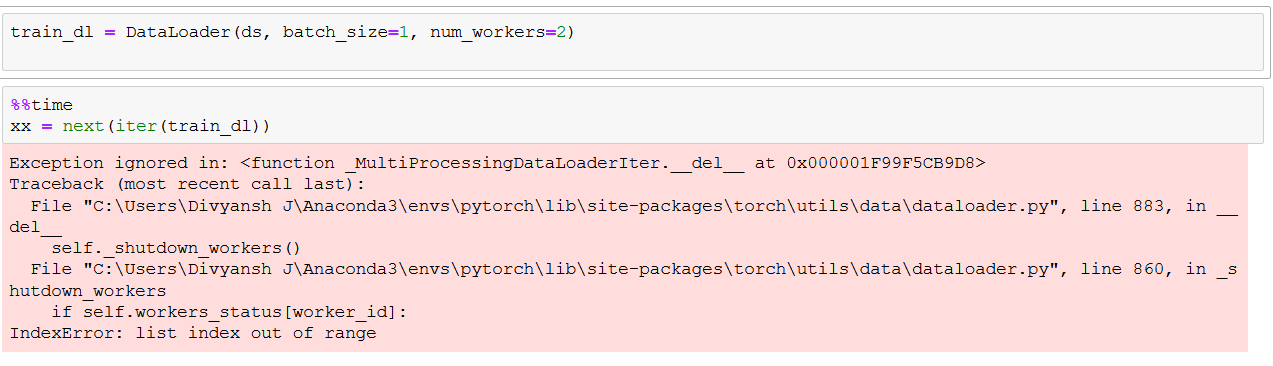
It works well with num_workers = 0, but does not work with num_worker>1
ds = Cifar100Dataset(path, train_folder, start=0, end=1024)
Exception ignored in: <function _MultiProcessingDataLoaderIter.__del__ at 0x000001F99F5CB9D8>
Traceback (most recent call last):
File "C:\Users\Divyansh J\Anaconda3\envs\pytorch\lib\site-packages\torch\utils\data\dataloader.py", line 883, in __del__
self._shutdown_workers()
File "C:\Users\Divyansh J\Anaconda3\envs\pytorch\lib\site-packages\torch\utils\data\dataloader.py", line 860, in _shutdown_workers
if self.workers_status[worker_id]:
IndexError: list index out of range
---------------------------------------------------------------------------
BrokenPipeError Traceback (most recent call last)
<timed exec> in <module>
~\Anaconda3\envs\pytorch\lib\site-packages\torch\utils\data\dataloader.py in __iter__(self)
240 return _SingleProcessDataLoaderIter(self)
241 else:
--> 242 return _MultiProcessingDataLoaderIter(self)
243
244 @property
~\Anaconda3\envs\pytorch\lib\site-packages\torch\utils\data\dataloader.py in __init__(self, loader)
639 # before it starts, and __del__ tries to join but will get:
640 # AssertionError: can only join a started process.
--> 641 w.start()
642 self.index_queues.append(index_queue)
643 self.workers.append(w)
~\Anaconda3\envs\pytorch\lib\multiprocessing\process.py in start(self)
110 'daemonic processes are not allowed to have children'
111 _cleanup()
--> 112 self._popen = self._Popen(self)
113 self._sentinel = self._popen.sentinel
114 # Avoid a refcycle if the target function holds an indirect
~\Anaconda3\envs\pytorch\lib\multiprocessing\context.py in _Popen(process_obj)
221 @staticmethod
222 def _Popen(process_obj):
--> 223 return _default_context.get_context().Process._Popen(process_obj)
224
225 class DefaultContext(BaseContext):
~\Anaconda3\envs\pytorch\lib\multiprocessing\context.py in _Popen(process_obj)
320 def _Popen(process_obj):
321 from .popen_spawn_win32 import Popen
--> 322 return Popen(process_obj)
323
324 class SpawnContext(BaseContext):
~\Anaconda3\envs\pytorch\lib\multiprocessing\popen_spawn_win32.py in __init__(self, process_obj)
87 try:
88 reduction.dump(prep_data, to_child)
---> 89 reduction.dump(process_obj, to_child)
90 finally:
91 set_spawning_popen(None)
~\Anaconda3\envs\pytorch\lib\multiprocessing\reduction.py in dump(obj, file, protocol)
58 def dump(obj, file, protocol=None):
59 '''Replacement for pickle.dump() using ForkingPickler.'''
---> 60 ForkingPickler(file, protocol).dump(obj)
61
62 #
BrokenPipeError: [Errno 32] Broken pipe
Also I want to know the usage of start, and end and what should be the batch_size I should pass in the Dataloader, because I am already specifying the start and end in Dataloader.