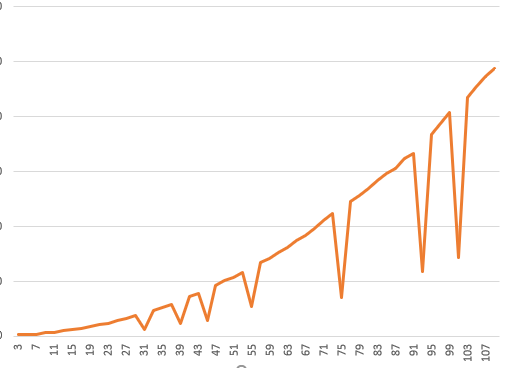
When testing the computational efficiency of convolution with different kernel sizes, it is found that when the kernel sizes are 3, 5 and 7, the computational efficiency is very high, but when the kernel size is greater than 7, the computational efficiency will be greatly reduced. In addition, when the kernel siezes are 31, 39, 45, 55, 75, 93, and 101, the efficiency will be higher than their adjacent sizes. What is the reason?
import numpy as np
import torch
from torch import nn
import time
h = 6115
w = 5490
pic = np.random.randint(0,2,(h,w),dtype=(np.int16))
Max_iters = 5
for kernel_size in range(3,110,2):
kernel = torch.ones((1,1,kernel_size,kernel_size))
neighbor_func = nn.Conv2d(1, 1, kernel_size,padding=int((kernel_size-1)/2),bias = False)
with torch.no_grad():
for i,j in neighbor_func.named_parameters():
j.copy_(kernel)
tst = time.time()
for i in range(Max_iters):
N = np.where(pic == 1,1,0)
N = np.reshape(N,(1,1,h,w))
N = torch.from_numpy(N).type(torch.float32)
with torch.no_grad():
N = neighbor_func(N)
N = N.detach().numpy()
N = np.squeeze(N)
print(kernel_size,time.time()-tst)
I want to use nn.Conv2d as a tool for convolution, which only performs convolution calculation on data without involving gradient calculation and back propagation, so which function can I choose to obtain the highest performance convolution in large kernel_sizes?