Can anyone help me convert this model to PyTorch? I’m just a beginner trying to do a college exercise. 
model.add(Dropout(0.05, input_shape=(497,128)))
model.add(Conv1D(filters=16, kernel_sizes=51, padding='valid', activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling1D(pool_size=2))
model.add(Dropout(0.6))
model.add(Conv1D(filters=18, kernel_size=51, padding='same', activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling1D(pool_size=2))
model.add(Dropout(0.6))
model.add(Bidirectional(LSTM(units=100), merge_mode='concat'))
model.add(Dropout(0.25))
model.add(Dense(units=2, activation='softmax'))
@ptrblck i’ve seen you a lot in the forums and i’ve learned a lot with you already. Can you help me out this time?
You should be able to directly post most of the layers and add them into an nn.Sequential container.
E.g. something like this would work:
model = nn.Sequential(
nn.Dropout(p=0.05),
nn.Conv1d(in_channels=TODO, out_channels=TODO, kernel_size=51, padding="valid", padding_mode=TODO),
nn.ReLU(),
nn.MaxPool1d(2),
...
)
There are a few differences, i.e. you would need to specify the input features/channels manually and would need to add the non-linearities as separate modules.
(You could also use nn.Lazy* modules in case you don’t want to calculate the input features/channels)
The main issue in porting would be the Bidirectional(LSTM) layer as I don’t know what exactly it’s doing in your code. PyTorch has an nn.LSTM module, which can also work in a bidirectional way via an input argument, but as it’ll return the output as well as the states I would not wrap it into an nn.Sequential container, but use a custom module for it so that you can make sure the outputs are processed in the desired way.
Hi @ptrblck, first of all thank you so much for the quick answer. I’ll provide some more information about the model’s implementation in the hope of a better understanding.
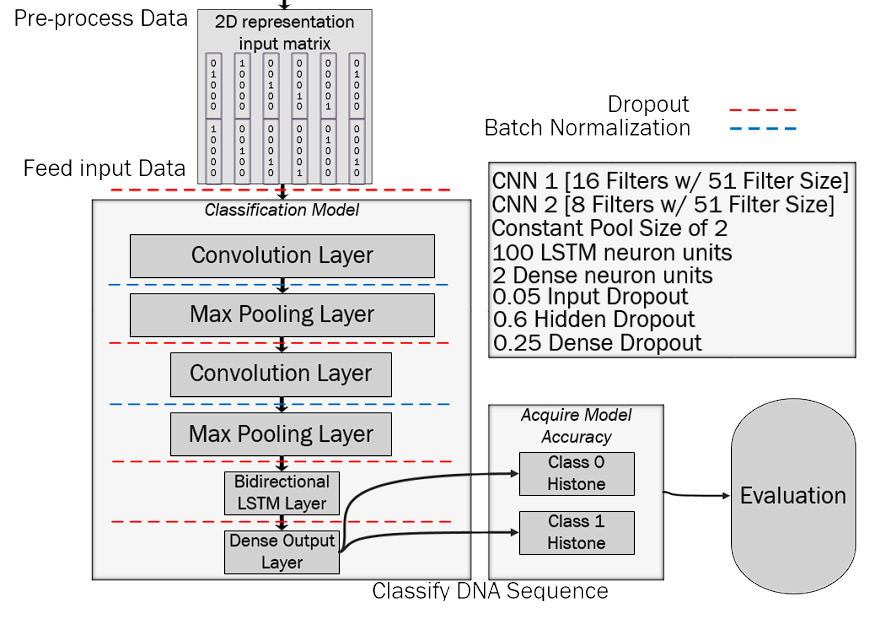
The model consists of 2 stacked convolutional layers for feature extraction, each followed by a max pooling subsampling layer. These layers sit on top of a Bi-Directional LSTM layer. Now, in order for these to be processed, the cut-down selected features will have to be forwarded to this layer’s units. Then, sequence prediction occurs. Dropout Regularization and Batch Normalization are applied in between layers, to reduce the model from overfitting and for better generalization on the test/validation set.
The following image represents the system architecture:
- Convolutional Layer - The classifier consists of two stacked convolutional layers, acting as a front-end part of this model. These interact directly with the pre-processed input, which has been numerically encoded as a matrix representation for feature extraction. Both layers consist of a number of filters which convolve across the 2D input training matrix. More specifically, the first Convolutional Layer has 16 filters with the filter size being 51 sequences long. This layer does not make use of any padding.
Similarly, the second Convolutional Layer has the same filter size; however, it does not require as many filters as before. So, the filter size is significantly reduced to 8 filters only. As opposed to when using the first convolutional layer, in the second convolutional layer, the input is padded in a way that the output and the original input are equal in length. Finally, both layers make use of the ReLU activation function which maps the output values in an eficient way.
-
Max Pooling Layer - Each Convolutional Layer is followed by a Max Pooling Layer of pool size 2, meaning that the input will be reduced by half. This is done on purpose to reduce complexity and dimensions, specifically by taking the maximum value from each of the cluster of neurons, situated at the prior layer. In fact, it is for this reason that it is known as the ‘Max’ Pooling Layer.
-
Bi-Directional LSTM Layer - This layer is applied to the features extracted from the convolutional layers. It consists of a Bi-Directional Layer of 100 LSTM neuron units, forming a forward as well as a backward pass on the features. Both passes will be merged together to produce one final result, via concatenation method. By performing an additional reversed pass, this layer overcomes limitations of a regular LSTM layer.
-
Dropout Regularization - To overcome the problem of overfitting, dropout layers of difierent values have been added to each layer of the model. This was done so that the model is able to generalise better predictions on the chosen validation/test set. Dropout is a technique that ignores an amount of components during the training process. It emphasizes the importance of quality over quantity.
The input dropout was set to a value of 0.05, while in the hidden layers, a dropout value of 0.6 was applied. Lastly, a final dropout layer of 0.25 was applied, prior to receiving the predictions from the dense layer.
-
Batch Normalization - Batch Normalization kicks this model up a notch, as it adds a normalization layer
after each convolutional layer. This allows the model to converge much faster in training, resulting in even higher learning rate. By the implementation of Batch Normalization, the problem of overfitting is minimised. This is why it is always recommended to use this technique.
-
Dense Layer - This layer is the last and final layer in the model. It consists of 2 neuron units, which represent the two difierent categorical classes. Hence, the sequences are either classified as [1,0] or [0,1]. In this layer, the `softmax’ activation function is utilised.
And that’s all the relevant information I have. In terms of code I only have that portion of the model available.
Once again, thank you