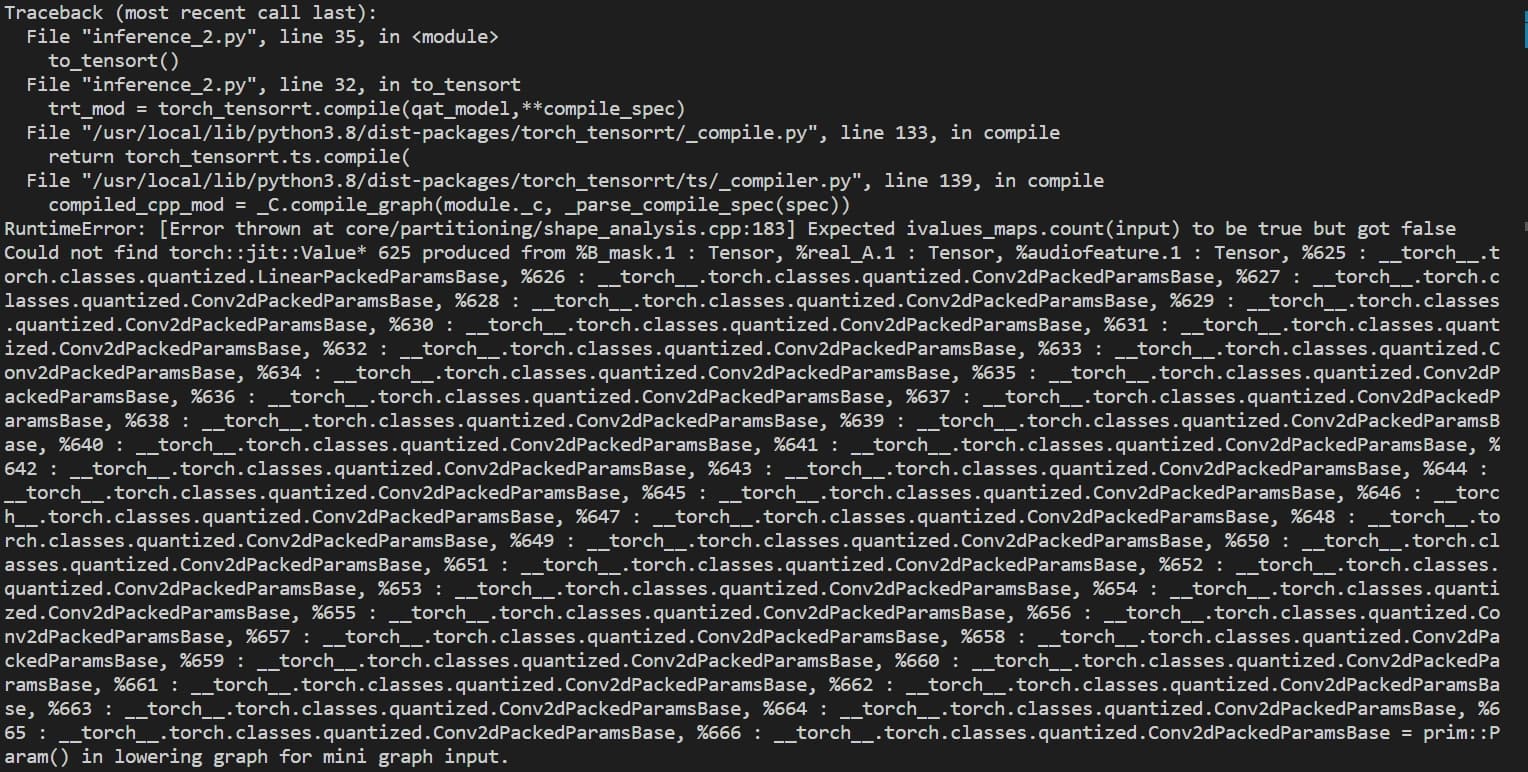
I ran quantized aware training in pytorch and convert the model into quantized with torch.ao.quantization.convert. I know pytorch does not yet support the inference of the quantized model on GPU, however, is there a way to convert the quantized pytorch model into tensorrt?
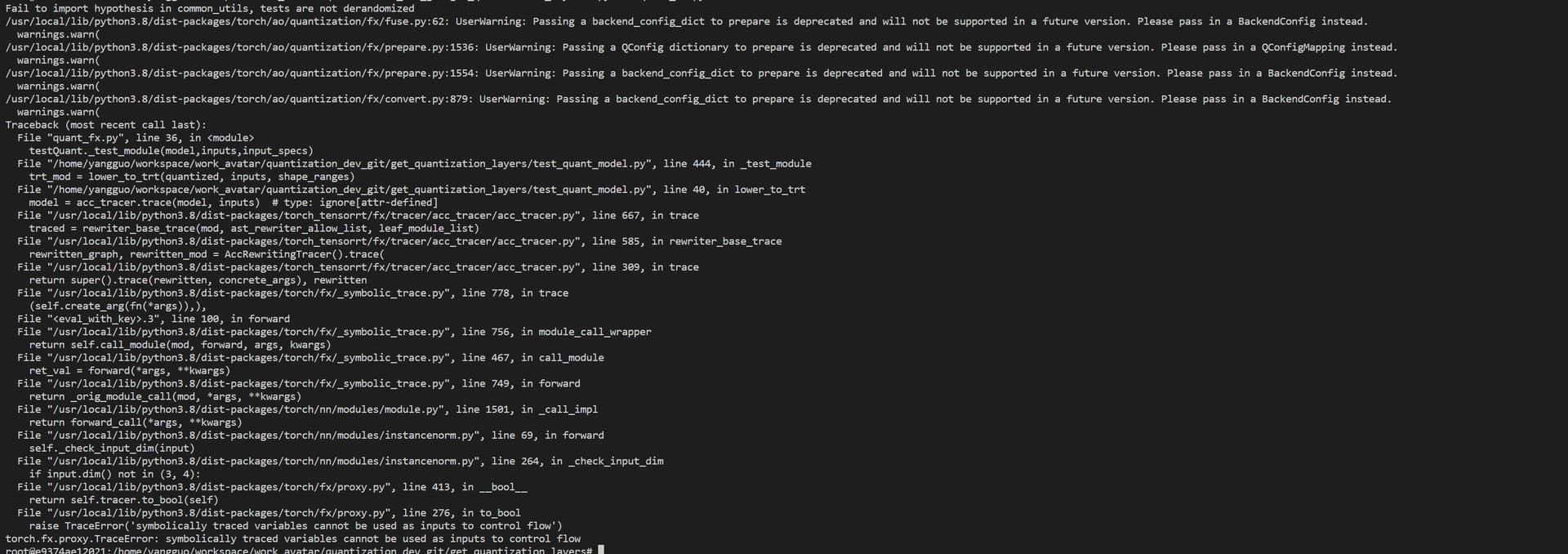
I already used fx quantization, but the conversion still failed. Is it because the pytorch quanization functionality is at early stage? Will the conversion of pytorch quantized model to tensorrt be easier in the future? Do you have any recommended tools for pytorch quantization and tensorrt distribution now?
It seems that the instancenorm module of pytorch contains conditional sentences if input.dim() not in (3, 4) that cannot be traced. Is it a bug of pytorch itself?
Hi, i know pytorch-quantization package can quantize our float model, but how to convert quantized model to onnx? And this onnx can be build by tensorRT or not ? Or do you have some hack method?