I am using aladdinperssons code for WGAN-GP: Machine-Learning-Collection/ML/Pytorch/GANs/4. WGAN-GP/train.py at master · aladdinpersson/Machine-Learning-Collection · GitHub
and removed the GP part and instead applied spectral normalization to both the critic and the generator as follows:
critic_fake = critic(fake).reshape(-1)
gp = gradient_penalty(critic, real, fake, device=device)
loss_critic = (
-(torch.mean(critic_real) - torch.mean(critic_fake)) + LAMBDA_GP * gp
)
critic.zero_grad()
becomes:
critic_fake = critic(fake).reshape(-1)
loss_critic = (
-(torch.mean(critic_real) - torch.mean(critic_fake))
)
critic.zero_grad()
and:
# initialize gen and disc, note: discriminator should be called critic,
# according to WGAN paper (since it no longer outputs between [0, 1])
gen = Generator(Z_DIM, CHANNELS_IMG, FEATURES_GEN).to(device)
critic = Discriminator(CHANNELS_IMG, FEATURES_CRITIC).to(device)
initialize_weights(gen)
initialize_weights(critic)
becomes:
# initialize gen and disc, note: discriminator should be called critic,
# according to WGAN paper (since it no longer outputs between [0, 1])
gen = Generator(Z_DIM, CHANNELS_IMG, FEATURES_GEN).to(device)
critic = Discriminator(CHANNELS_IMG, FEATURES_CRITIC).to(device)
initialize_weights(gen)
initialize_weights(critic)
apply_spectral_norm(gen)
apply_spectral_norm(critic)
Where apply_spectral_norm() is defined as:
def flatten_network(net):
flattened = [flatten_network(children) for children in net.children()]
res = [net]
for c in flattened:
res += c
return res
def apply_spectral_norm(net):
# Apply spectral normalization for conv layers
for p in flatten_network(net):
if isinstance(p, (nn.Conv2d, nn.ConvTranspose2d, nn.Linear)):
nn.utils.spectral_norm(p)
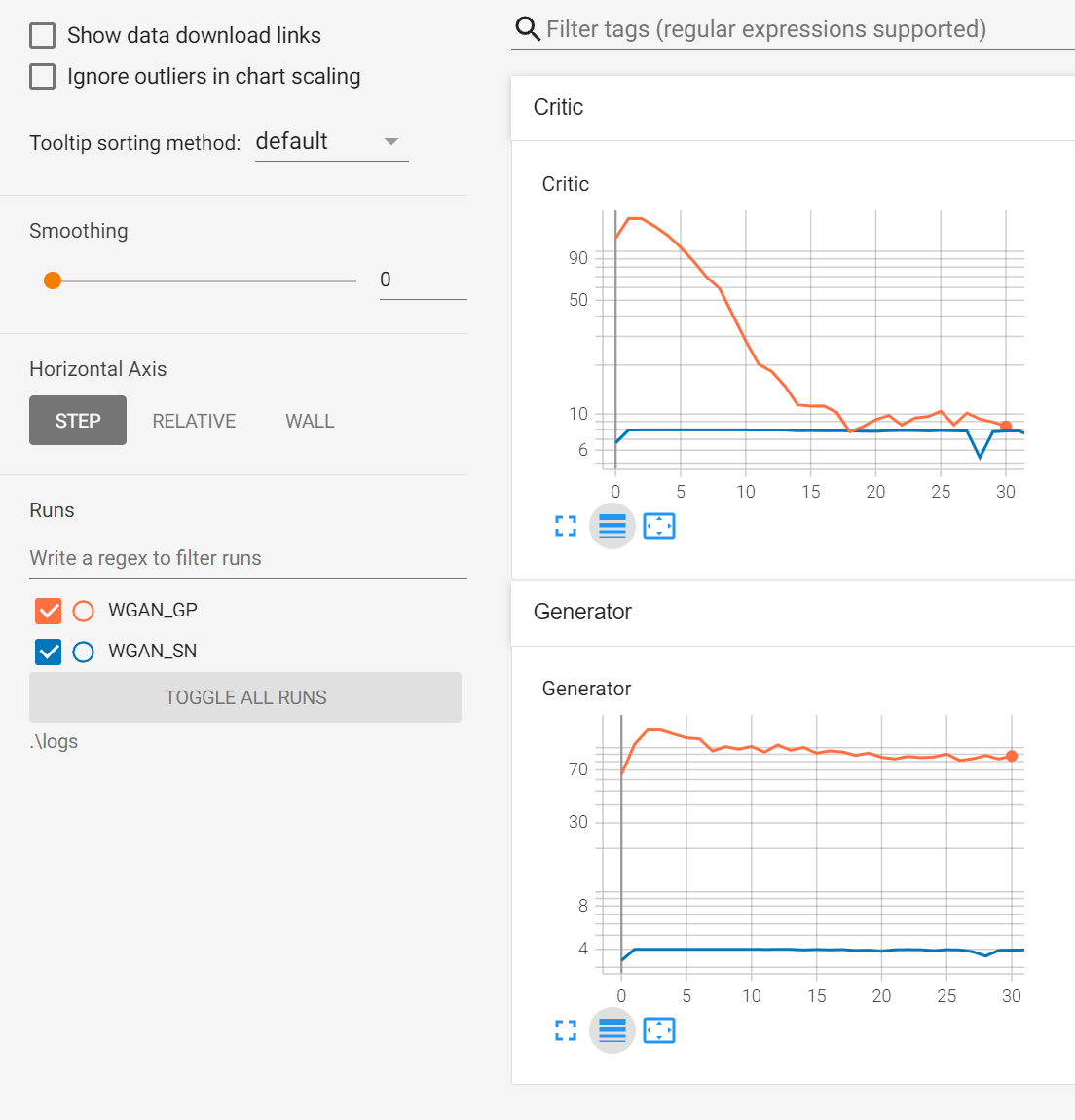
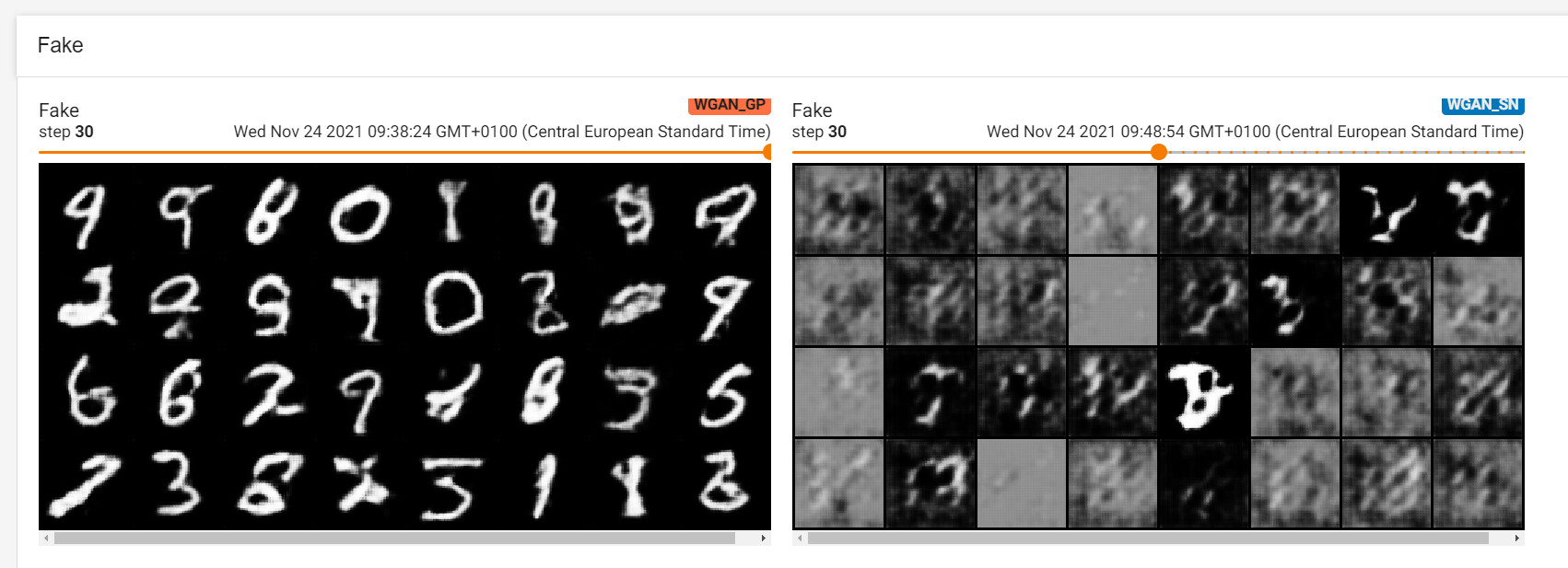
I expected the GAN to converge in similar speed but this is what I see:
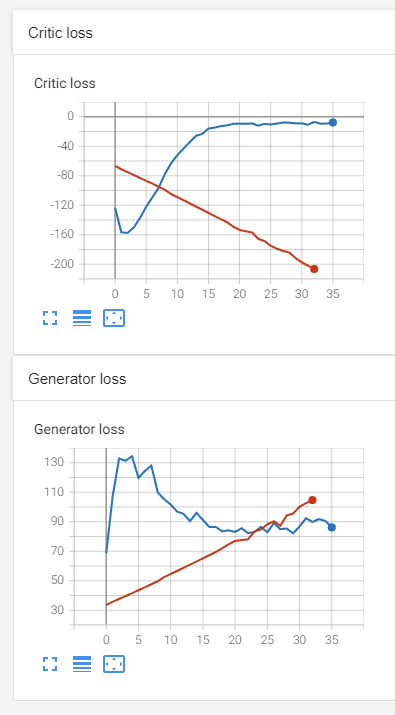
(blue is WGAN-GP and red is WGAN-SN)
Any tips on what I am missing?