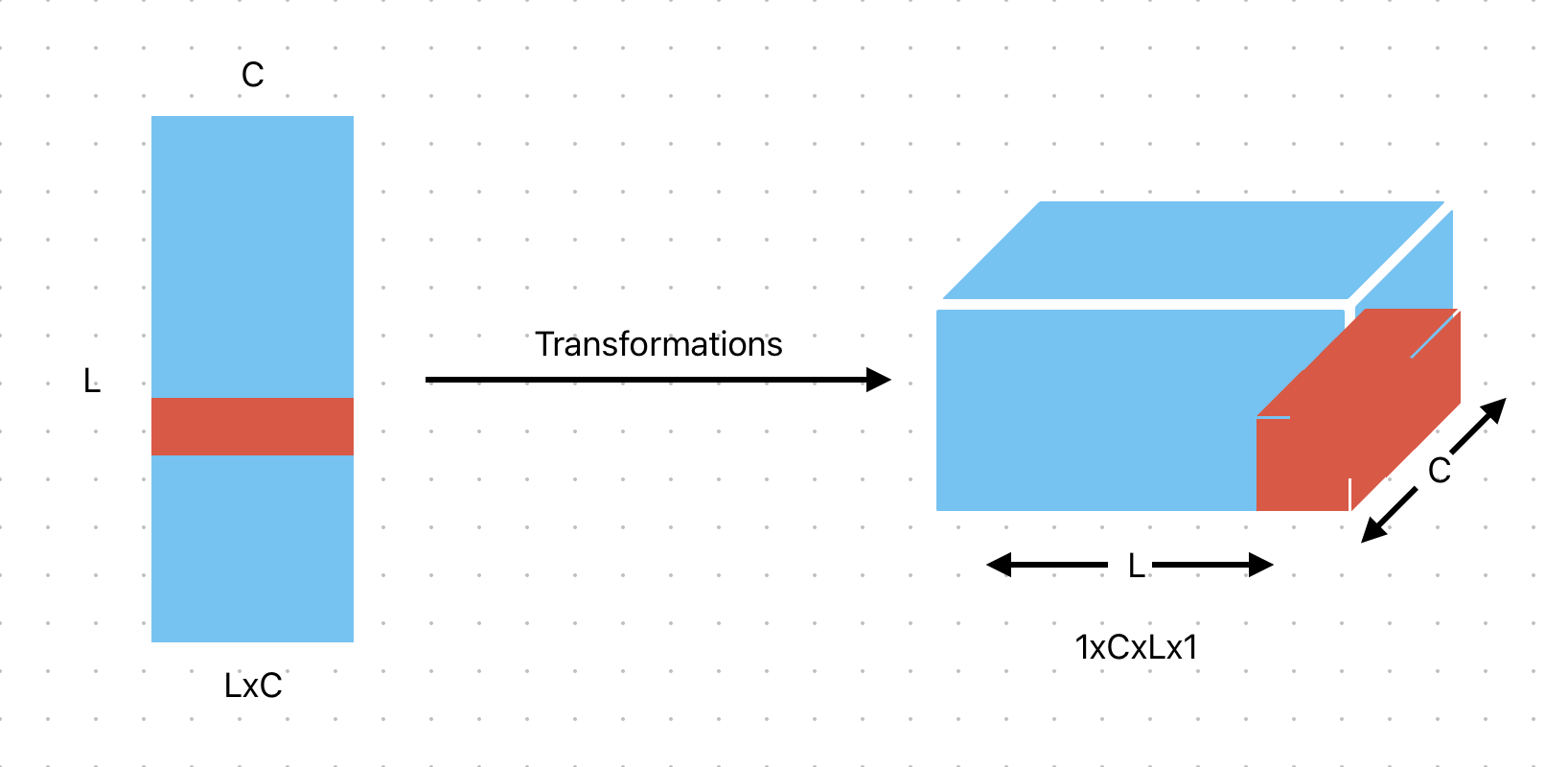
Hi K. Frank,
Thank you for your reply! I have attached a simple script. I am trying to get the e_output to match g_output. I have also attached a visual illustration of what I am trying to do with the matrix as well. Using permute, I end up bunching together the first value from
I appreciate the insight and help!
import torch
L = 60000
C = 128
tensor_2D = torch.randn(L,C)
tensor_4D = tensor_2D.data.unsqueeze(0).unsqueeze(-1).permute(0,2,1,3)
tensor_2D, tensor_4D[0][0], tensor_2D[0]
Output:
(tensor([[-0.9203, -0.5730, 0.4688, ..., -1.6398, -0.3495, -0.0658],
[ 0.6133, -0.2353, -0.6844, ..., 0.0541, -0.2642, -1.6251],
[ 0.7498, -0.5778, -1.2933, ..., 0.6337, -0.8241, 1.9411],
...,
[-0.5282, 2.1966, 0.9805, ..., -0.6725, -0.6689, 1.1485],
[-0.7611, 0.0720, 0.1070, ..., 1.4691, 0.5665, -0.4897],
[ 0.4414, 0.0610, -1.5197, ..., -1.4009, -0.4101, 0.1082]]),
tensor([[-0.9203],
[ 0.6133],
[ 0.7498],
...,
[-0.5282],
[-0.7611],
[ 0.4414]]),
tensor([-0.9203, -0.5730, 0.4688, 0.7558, -0.0483, -0.7688, -0.0693, 1.0376,
2.4042, -0.3007, -0.8850, 0.3835, 0.8781, 0.3174, -1.0734, -0.0287,
-1.4459, -0.6875, 0.3105, 0.9651, 1.9093, 0.1718, -0.7249, 0.8602,
1.1302, 0.4596, -0.1718, -0.4428, -0.1168, -1.0659, 0.3917, 0.0737,
1.2247, -1.6025, 0.4712, 0.5392, -0.8835, 1.7168, 0.3307, -0.0836,
1.7518, 0.5871, -0.0171, 0.1820, -0.0171, -0.3980, -0.3315, -0.6369,
0.5448, -0.4139, -1.6431, -0.3533, -0.5043, 0.3944, 1.3845, -0.4939,
-1.0925, 0.0763, -0.9511, 1.2899, 1.5805, 0.7202, 0.1146, 1.1339,
-0.7482, 2.1890, 0.3551, -1.9820, 0.5496, -0.6619, -1.0239, 1.1724,
1.1881, -1.3345, 0.0237, 1.9488, -1.5924, -0.3576, 0.2485, 0.4805,
1.8664, -0.8312, 1.1447, -1.2070, -1.0071, 0.4795, -0.9977, 0.2653,
0.8654, -0.5748, 0.9977, -0.5095, -0.8119, -0.5604, 0.9006, 0.3391,
1.5522, 1.1773, 0.0244, -1.4265, 0.0526, 0.3777, 1.6553, -0.4786,
-0.9769, -0.6977, -1.0240, 1.5423, 0.8922, 1.3467, -0.4278, 1.3876,
-1.5790, -1.1220, 2.0624, 0.6103, 0.7713, 0.2780, 0.9061, -1.3642,
0.7891, -2.5755, -0.4350, 0.0559, 0.7300, -1.6398, -0.3495, -0.0658]))
As you can see, instead of being a culmination of the rows, it is instead a culmination of the columns. I would like for the tensor_4D[0][0] to contain the same values as tensor_2D[0].