I have many txt files, each containing the pixels values of dimensions 28 by 28. How can I create a Dataloader for them that I will feed to a GAN model
Hello,
can you show the content or formatting inside one text file ?
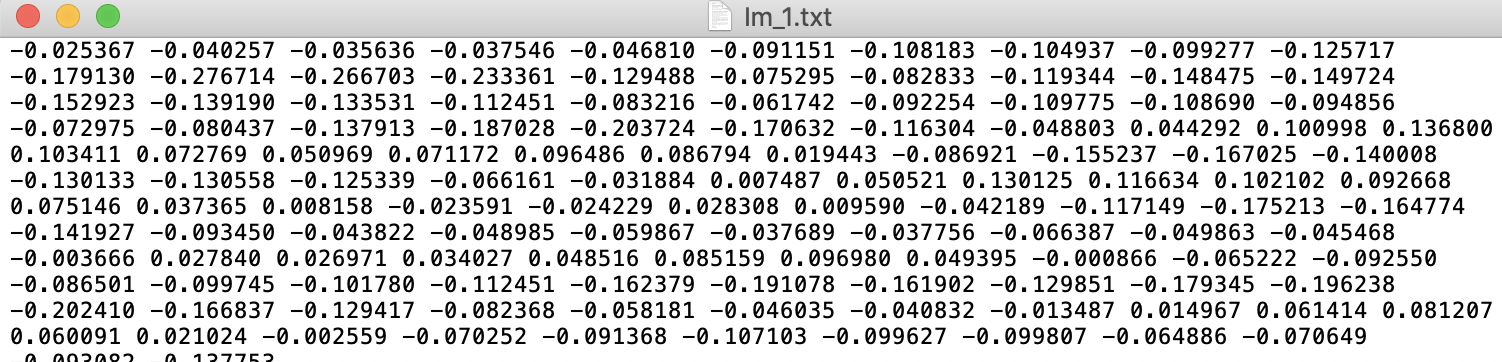
I have attached the screen shot
In order to extract the pixels values from the file, we need to know how to extract one pixel value.
which color domain is used? is it a color pixel rgb or bgr ? or grayscale ? or …?
In the mean time, the float values (that are between -1 and 1?) can be extracted using a whitespace separator. The idea would be to do something like this:
with open("Im_1.txt", "r") as fd:
content = fd.readlines().strip()
# each row is split into a list of string representing float numbers
# then each string is converted to a float with map(float, ...)
pixel_values = [map(float, row.split(" ")) for row in content]
Now, IF the image is grayscale, the list pixel_values and contains 28 rows of 28 elements, we obtain the tensor:
image = torch.tensor(pixel_values)
Thank you for the answer and these are rgb values and how can I make a Dataloader for list of txt files like we have for images in a folder
Hello,
ok then it means, it is possible to group the float values by 3 to get color pixels assuming the floats are gathered in a list and that this is the original intended format for the file.
Now a solution would be to subclass the torch.utils.data.Dataset class:
import itertools
from torch.utils.data import Dataset, DataLoader
def chunks(lst, n):
"""Yield successive n-sized chunks from lst."""
for i in range(0, len(lst), n):
yield lst[i:i + n]
class TextDataset(Dataset):
def __init__(self, text_file_paths, other_arguments):
self.paths = text_file_paths
# other processing you may want
...
def __len__(self):
return len(self.paths)
def __getitem__(self, idx):
path = self.paths[idx]
with open(path, "r") as fd: # EDIT
content = fd.readlines().strip()
pixel_values = [map(float, row.split(" ")) for row in content]
# all float values in one list
all_float_values = list(itertools.chain.from_iterable(pixel_values)))
# group the float values by 3
color_pixels = list(chunks(all_float_values, 3))
# again, split this color_pixels into a list of 28 elements
image = list(chunks(color_pixels, 28))
return torch.tensor(image)
StackOverflow links:
Finally
text_ds = TextDataset(your_text_file_paths_list, ...)
mydataloader = DataLoader(text_ds, batch_size=16, shuffle=True)
Hope it helps
Thank you so much. I really appreciate it.