Hello everyone,
I am sorry for the long post but would really appreciate any help you guys can offer !
I am trying to create a custom RNN that would apply n different recurrent connections (that are in fact n biquadratic filters) on the input. Another way of thinking about it would be to have n different RNN that works on the input and to concatenate thair results afterwards, however I believe that would lead to very poor performances (please tell me if I am wrong).
For instance :
I have a mini-batch of size [32, 16000], and want to apply 128 filters on it, which means that my output size is [32,128,16000].
What I did so far is :
- Expand and clone the input so I have a tensor of size : [32, 128, 16000].
- Permute axes to get a size of [16000, 32, 128].
- Iterate on the sequence and use matrices products to compute the input, since the filters are linears. In fact, I use this recurrence relation that works for only one sequence of size N (except the first two samples ofc) :
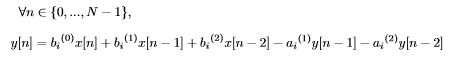
where the a_i and b_i are the learnable weights, x[n] is the n-th sample of the input, y[n] is the state at the time frame n, and i is for the i-th filter (or the i-th recurrence relation if you prefer).
I already tried two methods to make it work (see below). The problem is that my versions are too slow and I don’t have a good enough understanding of pytorch to optimize them.
So I would really appreciate any help you can provide on these points :
- Is there a better way of implementing an RNN with n different recurrence relations ?
- Do you see improvements I could make to my code (see below) that would yield to good performances ?
- May computing the outputs of the different RNNs in parallel and concatenate (with torch.cat) the results yield to better results ?
- May implementing in C++ (as it is the case for pytorch for the recurrence relation) become necessary to achieve good performance ?
Links for the pytorch RNN :
- RNN.py
- RNN.cpp
- QuantizeLinear.cpp which seems to contain the function that achieve the loop on the sequence : fbgemm_linear_int8_weight_fp32_activation.
Please, tell me if there is anything unclear or if you need more info.
Thanks for reading this post, and thanks for any piece of advice you can provide !
Code :
In each of the following version, the loop on the sequence is the piece of code that is the longest to execute.
- Version A :
def forward(self, X) :
bs = X.size()[0]
X = X.unsqueeze(1).expand(-1,self.kernels_number,-1).clone()
B0, A1, A2 = self.filters()
if(self.is_cuda):
out = torch.zeros(self.points_per_sequence, bs, self.kernels_number).cuda()
else:
out = torch.zeros(self.points_per_sequence, bs, self.kernels_number)
out[0] = torch.mul(X[0],B0) # [bs,1]*[1,128] = [bs,128]
out[1] = torch.mul(X[1],B0) - torch.mul(out[0],A1)
for n in range(2, X.size()[0]):
out[n] = self.f_2(out[n-1], out[n-2], X[n], X[n-2], B0, A1, A2)
out = torch.flip(out, dims=[2]).permute(1,2,0)
return out
(Since I am using pass-band filters, I only need the three tensors B0, A1, A2 of size [1,n_channels] each, there are computed from only two weights but it does not matter here).
The function self.f_2 :
def f_2(self, y_1, y_2, x, x_2, b0, a1, a2):
"""
Computing y[n] with y[n-1], y[n-2], x[n], x[n-1], x[n-2], b0, a1, a2
Sizes :
x : [bs,128]
b0,a1,a2 : [1,128]
y_1, y_2 : [bs, 128]
"""
return torch.mul(x-x_2,b0) - torch.mul(y_1,a1) - torch.mul(y_2,a2)
I have not tried this version on the backward pass but the forward pass works.
- Version B :
For this one, I used the function lfilter from torchaudio. Since the filters are all differents, I started by looping over the filters and applying lfilter which did not work well : it took longer than the previous version and had RAM issues.
Then I modified the function lfilter so it now accepts different filters. It now behaves, performance wise, as the version A.
Here is my version of the filter :
def m_lfilter(
waveform: torch.Tensor,
a_coeffs: torch.Tensor,
b_coeffs: torch.Tensor
) -> torch.Tensor:
r"""Perform an IIR filter by evaluating difference equation.
NB : contrary to the original version this one does not requires normalized input and does not ouput normalized sequences.
Args:
waveform (Tensor): audio waveform of dimension of `(..., number_of_filters, time)`.
a_coeffs (Tensor): denominator coefficients of difference equation of dimension of `(n_order + 1)`.
Lower delays coefficients are first, e.g. `number_of_filters*[a0, a1, a2, ...]`.
Must be same size as b_coeffs (pad with 0's as necessary).
b_coeffs (Tensor): numerator coefficients of difference equation of dimension of `(n_order + 1)`.
Lower delays coefficients are first, e.g. `number_of_filters*[b0, b1, b2, ...]`.
Must be same size as a_coeffs (pad with 0's as necessary).
Returns:
Tensor: Waveform with dimension of `(..., number_of_filters, time)`.
Note :
The main difference with the original version is that we are not packing anymore the batches (since we need to apply different filters)
"""
shape = waveform.size() # should returns [batch_size, number_of_filters, size_of_the_sequence]
assert (a_coeffs.size(0) == b_coeffs.size(0))
assert (len(waveform.size()) == 3)
assert (waveform.device == a_coeffs.device)
assert (b_coeffs.device == a_coeffs.device)
device = waveform.device
dtype = waveform.dtype
n_channel,n_filters, n_sample = waveform.size()
n_order = a_coeffs.size(1)
assert (a_coeffs.size(0) == n_filters) # number of filters to apply - for each filter k, the coefs are in a_coeffs[k] and b_coeffs[k]
n_sample_padded = n_sample + n_order - 1
assert (n_order > 0)
# Pad the input and create output
padded_waveform = torch.zeros(n_channel, n_filters, n_sample_padded, dtype=dtype, device=device)
padded_waveform[:,:,(n_order - 1):] = waveform
padded_output_waveform = torch.zeros(n_channel, n_filters, n_sample_padded, dtype=dtype, device=device) # padded_output_waveform = torch.zeros(n_channel, n_sample_padded, dtype=dtype, device=device)
# Set up the coefficients matrix
# Flip coefficients' order
a_coeffs_flipped = a_coeffs.flip(1).unsqueeze(0)
b_coeffs_flipped = b_coeffs.flip(1).t()
# calculate windowed_input_signal in parallel
# create indices of original with shape (n_channel, n_order, n_sample)
window_idxs = torch.arange(n_sample, device=device).unsqueeze(0) + torch.arange(n_order, device=device).unsqueeze(1)
window_idxs = window_idxs.repeat(n_channel, 1, 1)
window_idxs += (torch.arange(n_channel, device=device).unsqueeze(-1).unsqueeze(-1) * n_sample_padded)
window_idxs = window_idxs.long()
# (n_filters, n_order) matmul (n_channel, n_order, n_sample) -> (n_channel, n_filters, n_sample)
A = torch.take(padded_waveform, window_idxs).permute(0,2,1) # taking the input coefs
input_signal_windows = torch.matmul(torch.take(padded_waveform, window_idxs).permute(0,2,1),b_coeffs_flipped).permute(1,0,2)
# input_signal_windows size : n_samples x batch_size x n_filters
for i_sample, o0 in enumerate(input_signal_windows):
windowed_output_signal = padded_output_waveform[:, :, i_sample:(i_sample + n_order)].clone() # added clone here for back propagation
o0.sub_(torch.mul(windowed_output_signal,a_coeffs_flipped).sum(dim=2))
o0.div_(a_coeffs[:,0])
padded_output_waveform[:, : , i_sample + n_order - 1] = o0
output = padded_output_waveform[:, :,(n_order - 1):]
return output
As for the the forward function :
def forward(self, X):
# creating filters
A, B = self.filters() # A = [[a1_0, a2_0, a3_0],...], A = [[b1_0, b2_0, b3_0],...] - size : [128, 3]
X = X.unsqueeze(1).expand(-1,self.kernels_number,-1).clone() # we have to expand the input to the size : [bs, n_filters, n_samples]
# applying the filters
X = m_lfilter(X,A,B)
return X
This method works for the backward pass even if it takes ages to perform (I am working on implementing the TBPTT in parallel to improve these algorithms).
