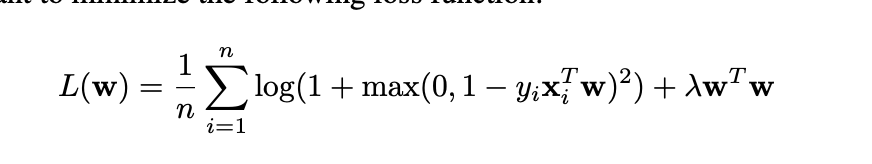I’m quite confused about how the optimizer created. From the Pytorch tutorial, when people implement SGD by defining a custom module first, which contains a constructor and a forward function, then using SGD optimizer to calculate the model parameters (please see the following code). My question is what if I am only given a loss function(please see the following pic) and I don’t have a “forward” function, how to create an optimizer? If my question is not clearly stated, please let me know and I’ll provide further information, thanks for any help in advance.
import torch
class model(torch.nn.Module):
def __init__(self, D_in, H, D_out):
super(model, self).__init__()
self.linear1 = torch.nn.Linear(D_in, H)
self.linear2 = torch.nn.Linear(H, D_out)
def forward(self, x):
h_relu = self.linear1(x).clamp(min=0)
y_pred = self.linear2(h_relu)
return y_pred
model = model(D_in, H, D_out)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4)