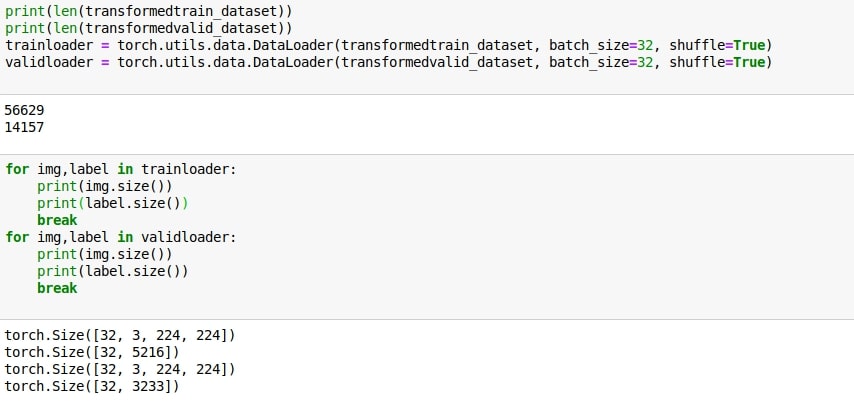
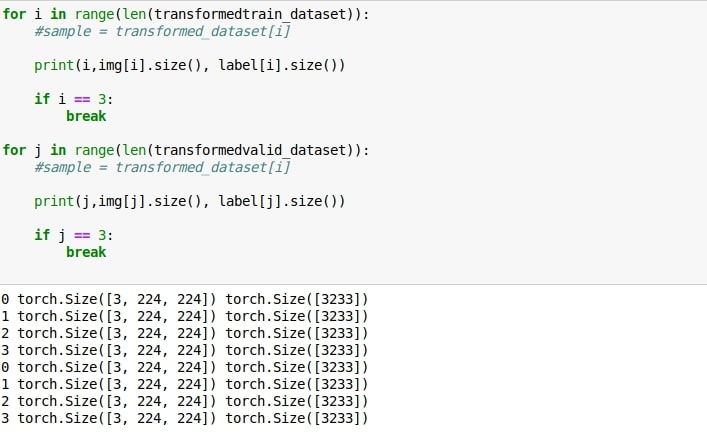
I have 3 separate image folders for train, test and validation set.
Both train and validation set have multiple labels of varying number.
The labels are provided in a .csv file where 1st column is filename of images in training set and second column has varying number of labels.
import torch
import pandas as pd
df= pd.read_csv(‘/home/nis/Downloads/trialdata/Training-Concepts.csv’,sep=‘;’,header=None)
print(df.head())
0 1
0 ROCO_CLEF_07350 C0203126,C0203051
1 ROCO_CLEF_19073 C0772294,C0023884,C0221198,C0412555,C0041618
2 ROCO_CLEF_60501 C0233492,C2985494,C0262950,C1306232
3 ROCO_CLEF_05564 C0521530,C0817096
4 ROCO_CLEF_55020 C0935598,C1184743
I created a custom dataset named myCustomDataset reading pytorch tutorials.
Is this approach right?
class myCustomDataset(Dataset):
“”“my dataset.”“”
def __init__(self, csv_file, root_dir, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.conceptframe = pd.read_csv(csv_file,sep=';',header=None)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.conceptframe)
def __getitem__(self, index):
img_name = os.path.join(self.root_dir,
self.conceptframe.iloc[index, 0])
image = io.imread(img_name)
label = self.conceptframe.iloc[index, 1]
sample = {'image': image, 'label': label}
if self.transform:
sample = self.transform(sample)
return sample
Now,I need to use transfer learning Resnet 50.
If, i am not wrong, I need to use nn.BCEloss
and i need to use sigmoid Function.
But I could not know how to use it.I was doubtful about it.
The maximum number of labels is 100 per image.
If i am not wrong, I should replace 2 with 100, in nn.linear() and logSoftmax with sigmoid.
Please let me know how to solve it.